
Authors:
(1) Gladys Tyen, University of Cambridge, Dept. of Computer Science & Technology, ALTA Institute, and Work done during an internship at Google Research (e-mail: gladys.tyen@cl.cam.ac.uk);
(2) Hassan Mansoor, Google Research (e-mail: hassan@google.com);
(3) Victor Carbune, Google Research (e-mail: vcarbune@google.com);
(4) Peter Chen, Google Research and Equal leadership contribution (chenfeif@google.com);
(5) Tony Mak, Google Research and Equal leadership contribution (e-mail: tonymak@google.com).
Table of Links
Conclusion, Limitations, and References
3 Benchmark results
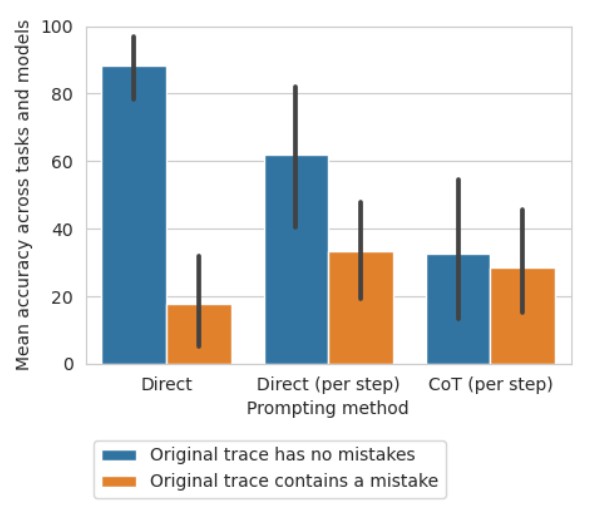
Table 4 shows the accuracy of GPT-4-Turbo, GPT4, and GPT-3.5-Turbo on our mistake-finding dataset. For each question, the possible answers are either that there are no mistakes, or, if there is a mistake, the number N indicating the step in which the first mistake occurs. A model’s output is only considered correct if the location matches exactly, or the output correctly indicates that there are no mistakes.
All models are given the same 3-shot prompts. We use three different prompting methods:
• Direct trace-level prompting involves using the whole trace as input to the model and directly prompting for the mistake location. The model must output either the number representing the step, or "No".
• Direct step-level prompting prompts for a binary Yes/No output for every step, indicating whether or not the step is correct. In each generation call, the input contains the partial trace up to (and including) the target step, but does not contain results for previous steps. The final answer is inferred from where the first "No" output occurs (subsequent steps are ignored).
• CoT step-level prompting is an extension of direct, step-level prompting. Instead of a binary Yes/No response, we prompt the model to check the (partial) trace through a series of reasoning steps. This method is the most resource intensive of all three methods as it involves generating a whole CoT sequence for every step. Due to cost and usage limits, we are unable to provide results from GPT-4-Turbo here. As with direct step-level prompting, the final answer is inferred from where the first "No" output occurs (subsequent steps are ignored).
3.1 Discussion
All three models appear to struggle with our mistake finding dataset. GPT-4 attains the best results but only reaches an overall accuracy of 52.87 with direct step-level prompting.
Our findings are in line with and builds upon results from Huang et al. (2023), who show that existing self-correction strategies are ineffective on reasoning errors. In our experiments, we specifically target the models’ mistake finding ability and provide results for additional tasks. We show that state-of-the-art LLMs clearly struggle with mistake finding, even in the most simple and unambiguous cases. (For comparison, humans can identify mistakes without specific expertise, and have a high degree of agreement, as shown in Table 2.)
We hypothesise that LLMs’ inability to find mistakes is a main contributing factor to why LLMs are unable to self-correct reasoning errors. If LLMs are unable to identify mistakes, it should be no surprise that they are unable to self-correct either.
Note that the mistakes in our dataset are generated using PaLM 2 L (Unicorn), and traces were sampled according to whether the final answer was correct or not. Therefore, we expect that using PaLM 2 itself to do mistake finding will produce different and likely biased results. Further work is needed to elucidate the difference between crossmodel evaluation and self-evaluation.
3.2 Comparison of prompting methods
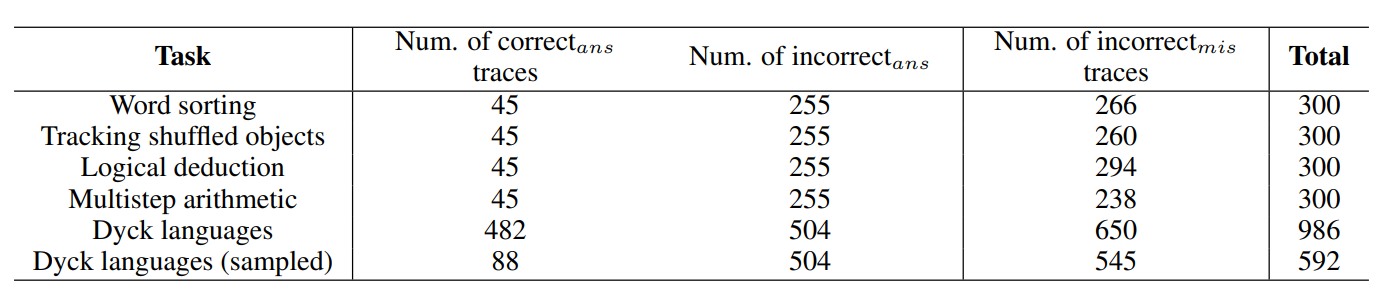
As we compare results across the three methods, we find that the accuracy on traces with no mistakes goes down7 considerably from direct, trace-level prompting to CoT, step-level prompting. Figure 1 demonstrates this trade-off.
We hypothesise that this is due to the number of outputs generated by the model. Our three methods involve generating increasingly complex outputs, starting with direct, trace-level prompting requiring a single token, then direct, step-level prompting requiring one token per step, and finally CoT step-level prompting requiring several sentences per step. If each generation call has some probability of identifying a mistake, then the more calls made on each trace, the more likely the model will identify at least one mistake.
3.3 Few-shot prompting for mistake location as a proxy for correctness
In this section, we investigate whether our prompting methods can reliably determine the correctnessans of a trace rather than the mistake location. Our motivation was that even humans use mistake finding as a strategy for determining whether an answer is correct or not, such as when going through mathematical proofs, or working through argumentation. Additionally, one might think that directly predicting the correctnessans of a trace may be easier than having to pinpoint the precise location of an error
We calculate averaged F1 scores based on whether the model predicts that there is a mistake in the trace. If there is a mistake, we assume the model prediction is that the trace is incorrectans. Otherwise, we assume the model prediction is that the trace is correctans.
In Table 5, we average the F1s using correctans and incorrectans as the positive label, weighted according to the number of times each label occurs. Note that the baseline of predicting all traces as incorrect achieves a weighted F1 average of 78.
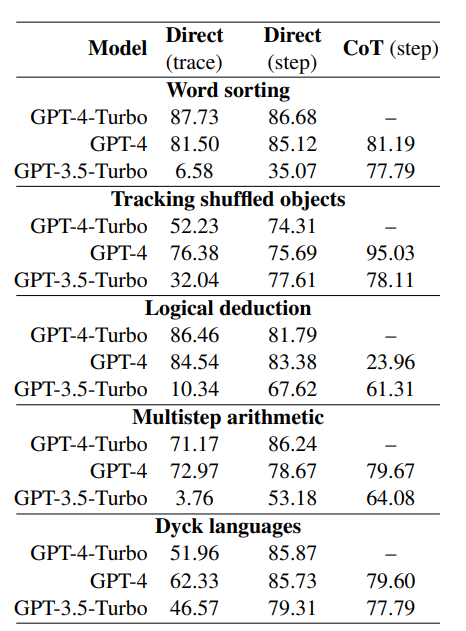
The weighted F1 scores show that prompting for mistakes is a poor strategy for determining the correctness of the final answer. This is in line with our previous finding that LLMs struggle to identify mistake locations, and also builds upon results from Huang et al. (2023), who demonstrate that improvements from Reflexion (Shinn et al., 2023) and RCI (Kim et al., 2023) are only from using oracle correctnessans information.
This paper is available on arxiv under CC 4.0 license.