
Let’s Start with the Data Story….
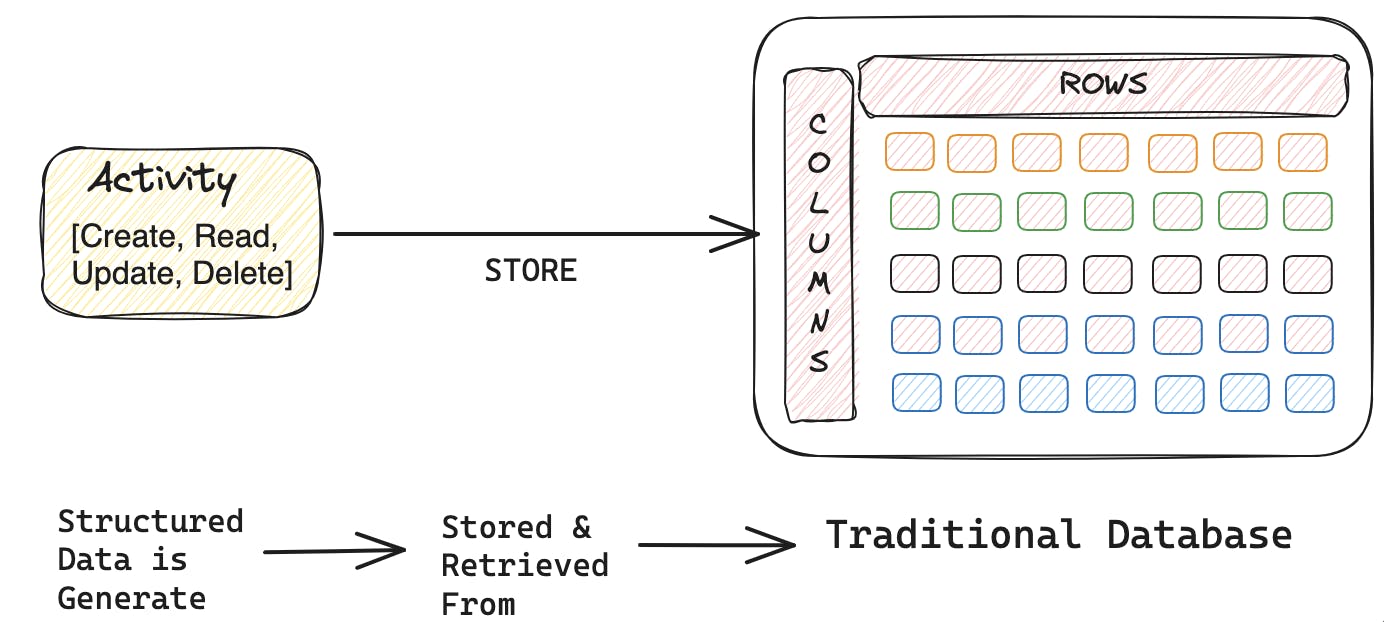
At the core of every software application, from the simplest to the most complex, operating at scale to serve millions of users with low-latency requests, lies a foundational element: data. For over three decades, relational database management systems (RDBMS) have been at the forefront of this domain. These systems, from simply storing data in a table format consisting of rows for records and columns for attributes, have undergone significant advancements and innovations that have revolutionized structured data and semi-unstructured storage. Relational database models have established themselves as the foundation of structured data handling, are renowned for their reliability, and battle-tested their efficacy in supporting massive big data scales for enterprise applications.
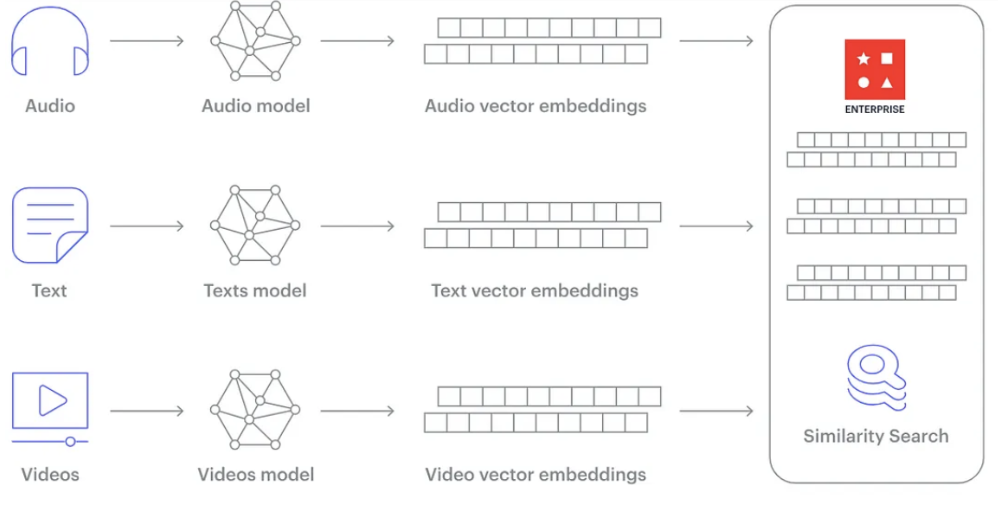
However, as we evolve deeper into the era of big data and artificial intelligence (AI), the limitations of traditional RDBMS in handling unstructured data, such as images, videos, audio, and natural language have become increasingly apparent. Enter the vector database, a cutting-edge innovation tailored for the age of AI and significantly change the recommendation systems. Unlike RDBMS, which excels in managing structured data, vector databases are designed to handle and query high-dimensional vector embeddings, a form of unstructured data representation that is central to modern machine learning algorithms.
Introduction: Vector DB
Vector embeddings allow complex data like text, images, and sounds to be transformed into numerical vectors, capturing the essence of the data in a way that machines can process. This transformation is crucial for tasks such as similarity search, recommendation systems, and natural language processing, where understanding the nuanced relationships between data points is key. Vector databases leverage specialized indexing and search algorithms to efficiently query these embeddings, enabling applications that were previously challenging or impossible with traditional RDBMS.
Fundamental Difference of RDBMS and Vectors
The application interacts with the database by executing various transactions and actions, which are stored in the form of rows and columns.
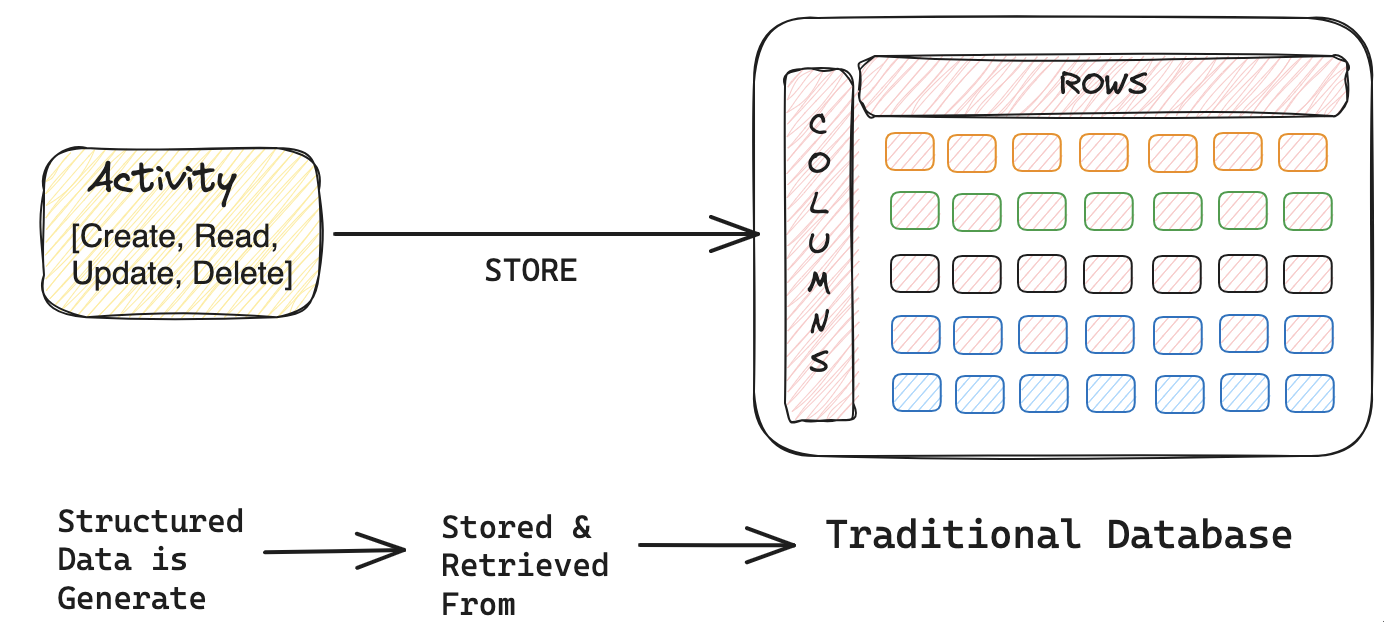
When it comes to the vector database, the action might look a bit different. Below, you can see the different types of files, which will be read and processed by many types of AI models and create vector embeddings.
Example in Action
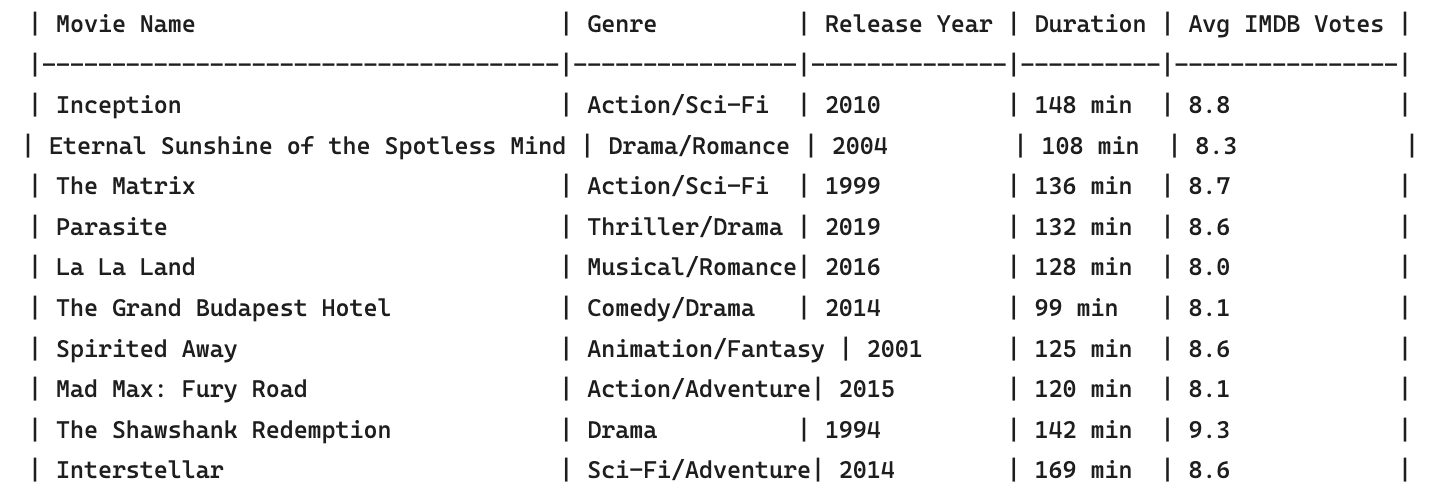
Consider the process of transforming a comprehensive movie database, such as IMDB, into a format where each movie is represented by vector embeddings and stored in a vector database. This transformation allows the database to leverage the power of vector embeddings to significantly enhance the user search experience. Because these vectors are organized within a three-dimensional space, search engineers can more efficiently perform queries across the movie database. This spatial organization not only streamlines the retrieval process but also enables the implementation of sophisticated search functionalities, such as finding movies with similar themes or genres, thereby creating a more intuitive and responsive search experience for users.
Now, we will demonstrate in Python how to convert textual movie data, similar to the tables mentioned above, into vector representations using BERT (Bidirectional Encoder Representations from Transformers), a pre-trained deep learning model developed by Google. This process entails several crucial steps for transforming the text into a format that the model can process, followed by the extraction of meaningful embeddings.
Let's break down each step.
Step 1
Python
import sqlite3
from transformers import BertTokenizer, BertModel
import torch
- sqlite3: This imports the SQLite3 library, which allows Python to interact with SQLite databases. It's used here to access a database containing IMDB movie information.
from transformers import BertTokenizer, BertModel:These imports from the Hugging Face transformers library bring in the necessary tools to tokenize text data (BertTokenizer) and to load the pre-trained BERT model (BertModel) for generating vector embeddings.import torch:This imports PyTorch, a deep learning framework that BERT and many other models in thetransformerslibrary are built on. It's used for managing tensors, which are multi-dimensional arrays that serve as the basic building blocks of data for neural networks.
Step 2
#Initialize Tokenizer and Model
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
tokenizer: This initializes the BERT tokenizer, configuring it to split input text into tokens that the BERT model can understand. Thefrom_pretrained('bert-base-uncased')method loads a tokenizer trained in lowercase English text.model: This initializes the BERT model itself, also using thefrom_pretrainedmethod to load a version trained in lowercase English. This model is what will generate the embeddings from the tokenized text.
Step 3
# Connect to Database and Fetch Movie Data
conn = sqlite3.connect('path/to/your/movie_database.db')
cursor = conn.cursor()
cursor.execute("SELECT name, genre, release_date, length FROM movies")
movies = cursor.fetchall()
conn = sqlite3.connect('path/to/your/movie_database.db'): Opens a connection to an SQLite database file that contains your movie datacursor = conn.cursor(): Creates a cursor object which is used to execute SQL commands through the connectioncursor.execute(...): Executes an SQL command to select specific columns (name, genre, release date, length) from themoviestablemovies = cursor.fetchall(): Retrieves all the rows returned by the SQL query and stores them in the variablemovies
Step 4
#Convert Movie Data to Vector Embeddings
movie_vectors = []
for movie in movies:
movie_data = ', '.join(str(field) for field in movie)
inputs = tokenizer(movie_data, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
movie_vector = outputs.last_hidden_state[:, 0, :].numpy()
movie_vectors.append(movie_vector)
movie_vectors = []: Initializes an empty list to store the vector embeddings for each movie- For loop: Iterates over each movie retrieved from the database
movie_data = ', '.join(...): Concatenates the movie's details into a single stringinputs = tokenizer(...): Uses the BERT tokenizer to prepare the concatenated string for the model, converting it into a tensorwith torch.no_grad():: Temporarily disables gradient computation, which is unnecessary during inference (model.predict)outputs = model(**inputs): Feeds the tokenized input to the BERT model to get the embeddingsmovie_vector = ...: Extracts the embedding of the[CLS]token, which represents the entire input sequencemovie_vectors.append(movie_vector): Adds the movie's vector embedding to the list
Output
-
movie_vectors: At the end of this script, you have a list of vector embeddings, one for each movie in your database. These vectors encapsulate the semantic information of the movies' names, genres, release dates, and durations in a form that machine learning models can work with.

Conclusion
In our example of vector database, movies such as "Inception" and "The Matrix" known for their action-packed, thought-provoking narratives, or "La La Land" and "Eternal Sunshine of the Spotless Mind," which explore complex romantic themes are transformed into high-dimensional vectors using BERT, a deep learning model. These vectors capture not just the overt categories like genre or release year, but also subtler thematic and emotional nuances encoded in their descriptions.
Once stored in a vector database, these embeddings can be queried efficiently to perform similarity searches. When a user searches for a film with a particular vibe or thematic element, the streaming service can quickly identify and suggest films that are "near" the user's interests in the vector space, even if the user's search terms don't directly match the movie's title, genre, or other metadata. For instance, a search for "dream manipulation movies" might not only return "Inception" but also suggest "The Matrix," given their thematic similarities represented in the vector space.
This method of storage and retrieval significantly enriches the user experience on streaming platforms, facilitating a discovery process that aligns content with both the user's interests and current mood. It’s designed to lead to "aha moments," where users uncover hidden gems, especially valuable when navigating the vast catalogs and offerings of streaming services. By detailing the creation and application of vector embeddings from textual movie data, we demonstrate the significant use of machine learning and vector databases in revolutionizing search capabilities and elevating the user experience in digital content ecosystems, particularly within streaming video services.