
Authors:
(1) Vahid Majdinasab, Department of Computer and Software Engineering Polytechnique Montreal, Canada;
(2) Michael Joshua Bishop, School of Mathematical and Computational Sciences Massey University, New Zealand;
(3) Shawn Rasheed, Information & Communication Technology Group UCOL - Te Pukenga, New Zealand;
(4) Arghavan Moradidakhel, Department of Computer and Software Engineering Polytechnique Montreal, Canada;
(5) Amjed Tahir, School of Mathematical and Computational Sciences Massey University, New Zealand;
(6) Foutse Khomh, Department of Computer and Software Engineering Polytechnique Montreal, Canada.
Table of Links
Replication Scope and Methodology
Conclusion, Acknowledgments, and References
III. REPLICATION SCOPE AND METHODOLOGY
Table I provides an overview of the experimental setups followed in the original study and in this replication. Details of our methodology for generating the CWE scenarios and our manual analysis are provided below.
A. Generating CWE scenarios using Copilot
In this study, we focus our experimental analysis on the Python language and analyzed scenarios related to twelve CWEs (details are shown in Table II). For each CWE, we adapted the scenarios from the original study of Pearce et al. [14]. The original study employed three distinct sources to develop these scenarios. The initial source includes CodeQL examples and documentation. The second source encompasses examples provided for each CWE in MITRE’s dataset. The final source involves scenarios designed by the author.
Copilot is prompted to complete each scenario by placing the cursor at the position where code completion is needed. It is important to note that these scenarios do not contain vulnerabilities; our objective is to examine whether the code added by Copilot to complete the scenarios introduces any vulnerabilities.
Our objective was to gather 25 solutions proposed by Copilot for each scenario. Although Copilot’s configuration in Visual Studio Code IDE [3] provides various settings, such as the option to define the maximum number of displayed solutions (ListCount), in the version (1.77.9225) utilized for this study, this parameter does not function as intended. Regardless of our attempts to set the maximum solutions anywhere from 10 to 100, the tool consistently returns a random quantity of solutions in each iteration. To address this limitation, we collect up to 55 solutions generated by Copilot for each scenario across multiple iterations.
Given that this study aims to investigate potential vulnerabilities in Copilot’s suggestions, our evaluation concentrates solely on identifying vulnerabilities within the provided suggestions rather than assessing their accuracy in addressing the prompts. However, it is important to note that some of the suggestions proposed by Copilot exhibit syntax errors. We excluded such suggestions from our evaluation process for two reasons. First, in order to scan them for security weaknesses using CodeQL, the code must be compilable. Moreover, in line with the original study [14] and the work of Dakhel et al. [5], there are potential instances of duplication in Copilot’s top-n suggestions. To address this issue, we adopted the same strategy as recommended in [5] to eliminate duplicates.

![TABLE II: List of CWEs examined [18]](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-jh93zcg.png)
This approach involves computing the similarity between the Abstract Syntax Trees (ASTs) of different suggestions, with an exclusion of the leaves corresponding to variable or function names (including all natural language content). In order to compare the ASTs of solutions, the codes must not contain any syntax errors and therefore we exclude those that cannot be compiled.
For removing the duplicate solutions, in cases where the similarity between two ASTs is identified as 1, we categorize them as duplicates and subsequently eliminate one of them. It is noteworthy that, in the original study [14], duplicates were removed by comparing the sequences of tokens, which resulted in the identification of distinct duplicate code snippets in their collected solutions, differing only in variable or function names or content of comments in different lines of codes. Using AST similarity to remove the duplicates between the suggested solutions allows us to have a more accurate understanding of Copilot’s faults.
B. Static Analysis with CodeQL
CodeQL analysis was conducted on a machine with an Intel Xeon E5-2690 v3 processor with a memory of 128GB DDR4 RAM running Ubuntu 20.04.5 LTS. The analysis took 16 minutes 37 seconds real-time. Automated Python scripts were used to run the database build and analysis tests based on parameters specific to each sample set/CWE. All scenarios and scripts used during our analysis were developed for Python 3.8.10. CodeQL version 2.12.4 of the command line toolchain was used for static security analysis. An example of CodeQL’s output for a vulnerability is shown in Fig. 1.
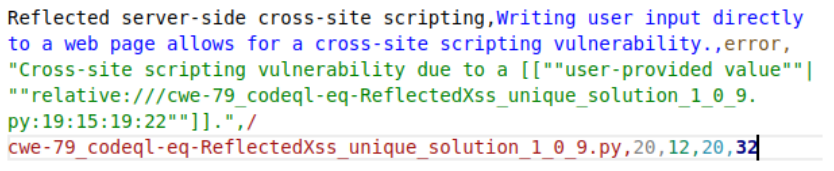
C. Manual Analysis
We conducted a manual analysis for the code suggestions that we could not analyze using CodeQL. We analyzed a total of 141 code samples related to four CWEs (i.e., CWE-434, CWE-306, CWE-200 and CWE-522). This manual analysis was conducted by two coders (both are coauthors). Both coders have experience with security analysis and have discussed the vulnerabilities and the review protocol before conducting the analysis. Each coder was assigned a set of code suggestions to validate whether they contained the specific CWE under investigation. The two coders first analyzed 12 code suggestions (3 suggestions for each of the four CWEs) to verify their classification and agree on the classification approach. Once both agreed on the classification, the coders thoroughly checked the assigned code suggestions individually. Once the individual tasks were completed, the coders cross-validated their classification by verifying five randomly selected suggestions for each CWE, totaling 20 suggestions. Of those 20 suggestions, both have agreed on 18 suggestions (reaching 90% agreement rate). The remaining two suggestions were resolved via discussion. We note that, for all code suggestions we analyzed, we focused only on the CWE under investigation, and we did not consider other potential security vulnerabilities that may impact the code. For example, when analyzing CWE-522 code suggestions, we did not consider the strength of the hashing algorithm implemented as we deemed it irrelevant to our analysis.
D. Limitations
As we are unable to determine the version of Copilot used in the original study, it is not possible for us to reproduce the same results (using the version of Copilot) as the original study.
We have had challenges related to Copilot API changes. We noted that the API changes to Copilot (in the latest versions) have made analyzing the generated code (through CodeQL static analysis) more difficult. Similarly, Copilot frequently generates non-runnable code, not allowing us to automatically run CodeQL on some code. Therefore, we ended up removing such code suggestions from our analysis.
Some CWEs in the original study, namely CWE-22 (TarSlip scenario) and CWE-798, were analyzed with custom CodeQL queries and these queries are no longer compatible with the version of CodeQL used in our study. Compatible queries that cover the same CWE’s were run on these scenarios.
E. Replication Package
We provide our full dataset, including all generated CWEs code scenarios, CodeQL databases, and other scripts in our repository at https://github.com/CommissarSilver/CVT.
This paper is available on arxiv under CC 4.0 license.
[3] https://code.visualstudio.com