
Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
6.3 Story Generation with Constraints
6.3.1 Introduction
Story generation is the task of generating a coherent narrative. Due to its open-ended nature, increasing efforts have been devoted to constrained settings to facilitate reliable evaluation of computational models, such as generating stories from short prompts (Fan et al., 2018b) and story continuations (Mostafazadeh et al., 2016) with various constraints (Akoury et al., 2020). In this work, we are interested in generating stories that accord with descriptions about the characters involved. The task is akin to writing stories based on true events or historical figures. For example, when writing historical fiction, writers use facts in biographies of historical figures (i.e., character descriptions) (Brown, 1998). In a similar vein, cognitive psychologists observed that in order for narrative text to be compelling, it has to base its characters on real-world details such that readers can form emotional attachments to them even if the events occurring in the text are not realistic (Oatley, 1999; Green et al., 2003). In either case, computational models for this task can offer assistance in proposing possible stories constrained by relevant documents.
To this end, we create a story generation dataset TVSTORYGEN that generates detailed TV show episode recaps from a brief summary of the episode and a set of lengthy character descriptions. We construct TVSTORYGEN from fan-contributed websites, which allows us to collect 26k episode recaps covering a variety of genres. An example from TVSTORYGEN is shown in Fig. 6.6. The dataset is challenging in that it requires drawing relevant information from the lengthy character description documents based on the brief summary. Since the detailed episode recaps are constrained by character descriptions, it also can evaluate neural models’ ability to maintain consistent traits or goals of particular characters during generation.
In addition, by considering generating the brief summary from the detailed recap, we show that TVSTORYGEN is a challenging testbed for abstractive summarization. To evaluate the faithfulness of the generated stories to the brief summaries, we propose a metric that uses the perplexities from the summarization model trained on our dataset.
Empirically, we characterize the dataset with several nearest neighbour methods and oracle models, finding that the use of the brief summaries and the character descriptions generally benefits model performance. We find that our non-oracle models are competitive compared to nearest neighbour models, suggesting promising future directions. We also benchmark several large pretrained models on the summarization version of our dataset, finding that they perform worse than an extractive oracle by a large margin despite the fact that the dataset favors abstractive approaches. Human evaluation reveals that without character descriptions, models tend to dwell on each event separately rather than advancing the plot, whereas using character descriptions improves the interestingness of the generated stories. Qualitatively, we show that models are able to generate stories that share similar topics with the summaries, but they may miss events in the summaries, leading to unfaithful generations.
We summarize our contributions below:
-
We construct a story generation dataset of 26k instances and show (both qualitatively and quantitatively) that it has several unique challenges.
-
We show that inverting our dataset provides a challenging testbed for abstractivesummarization. Models trained on the inverted dataset can be used in evaluation for the original dataset, namely to determine whether generated stories are faithful to their input summaries.
-
We empirically characterize the story generation dataset and the summarization version of our dataset with several nearest neighbour methods, oracle models, and pretrained models, showing the challenges of these tasks and suggesting future research directions.
6.3.2 Related Work
Early methods in computational modeling for story generation rely on handwritten rules (Meehan, 1977; Liu and Singh, 2002) to structure narrative. Recent work has explored different approaches to improve the quality of story generation systems, including commonsense knowledge (Mao et al., 2019; Guan et al., 2020), automatically extracted key words (Peng et al., 2018) and key phrases (Orbach and Goldberg, 2020; Rashkin et al., 2020), event-based representations (Martin et al., 2018), and plot graphs (Li et al., 2013).
As our model involves plot generation and character modeling, it is related to work on plot planning (Riedl and Young, 2010; Li et al., 2013; Martin et al., 2018; Yao et al., 2019; Jhamtani and Berg-Kirkpatrick, 2020), character modeling (Clark et al., 2018; Liu et al., 2020a), and the interplay between the two (Riedl and Young, 2010). Our work is different in that it explicitly requires performing inference on lengthy documents about characters.
There have been other datasets built from TV shows, such as summarizing TV show character descriptions (Shi et al., 2021b), constructing knowledge bases (Chu et al., 2021a), summarizing TV show screenplays (Chen et al., 2022a), entity tracking (Chen and Choi, 2016; Choi and Chen, 2018), entity linking (Logeswaran et al., 2019), coreference resolution (Chen et al., 2017; Zhou and Choi, 2018), question answering (Ma et al., 2018a; Yang and Choi, 2019), speaker identification (Ma et al., 2017), sarcasm detection (Joshi et al., 2016), emotion detection (Zahiri and Choi, 2017; Hsu and Ku, 2018), and character relation extraction (Yu et al., 2020).

6.3.3 TVSTORYGEN
In this section, we describe how we construct TVSTORYGEN and compare it to other story generation datasets. An instance in TVSTORYGEN is comprised of three components: (1) a detailed episode recap, (2) a brief summary of the episode, and (3) character descriptions, i.e., a set of documents describing the characters involved in the episode. The detailed episode recap delineates the events that occurred in the corresponding episode, which is usually written by fans after watching the episode. The documents about the characters contain biographical details and possibly personality traits. The summary either summarizes the whole episode or talks about the setup of the episode (to avoid spoilers).
An example instance is shown in Fig. 6.6, which comes from an episode of the TV show “The Simpsons”. As there are relevant details mentioned in the character descriptions, generating the detailed recap requires drawing information from the lengthy character descriptions about the two characters. Moreover, due to the fact that the brief summary only depicts the setup of the episode, completing the story also necessitates using information in the character descriptions. That is, the character description information is expected to be useful for both filling in details that are not present in the brief summary as well as, for some of the instances, generating a plausible ending for the story.
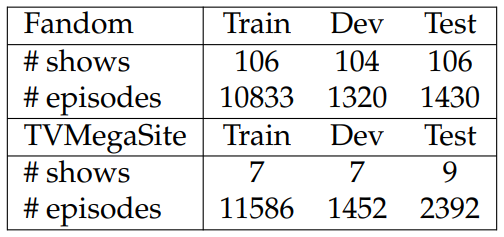
Dataset Construction. We construct TVSTORYGEN from two fan-contributed websites: Fandom[20] (FD) and TVMegaSite[21] (TMS). We collect brief summaries and detailed episode recaps for several long-running soap operas from TVMegaSite and other TV shows from Fandom. We collect character descriptions from Fandom.[22] Since the pages on Fandom have hyperlinks pointing to the character pages, we use the hyperlinks to connect episodes to the characters involved. For TVMegaSite,
where there are no such hyperlinks, we use string matching to find the characters. To ensure the quality of this dataset, we filter out episodes based on several criteria. See the appendix for more details on the criteria and the string matching algorithm.
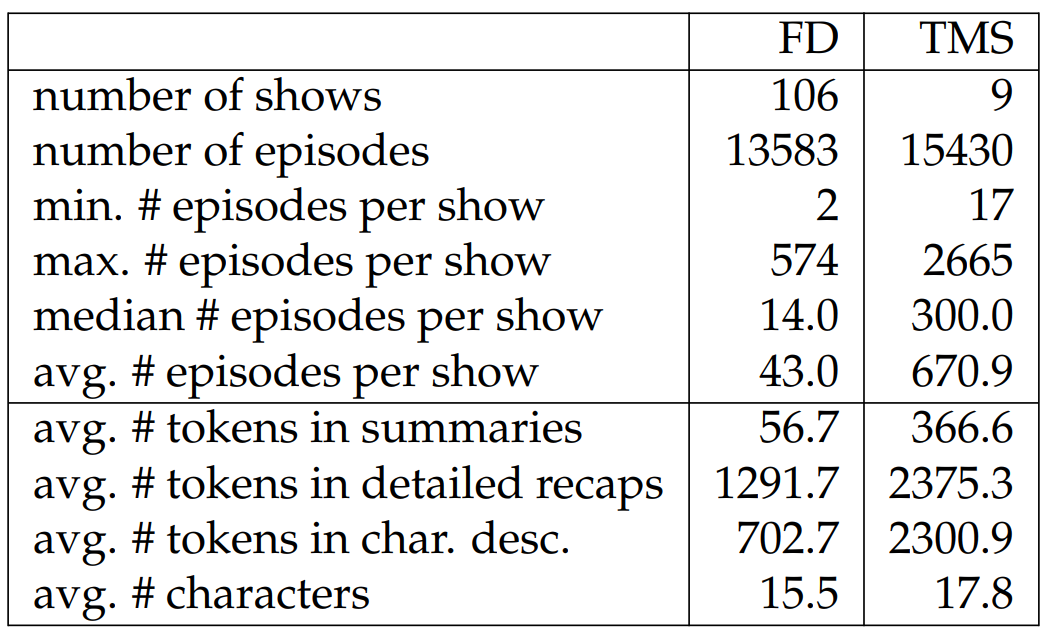
We report detailed statistics about TVSTORYGEN in Table 6.24. As shown in the table, there are systematic differences between FD and TMS in terms of length of detailed episode recaps, summaries, and character descriptions, among others. We note that the character descriptions for TMS also come from FD. Considering the differences, we train and evaluate models on the two splits separately in experiments. Since the summaries in Fandom are shorter and likely only depict the setups of the detailed recaps, we conduct a human evaluation to check the fraction of setups in the summaries, finding that 61.7% of the summaries are setups.[23]
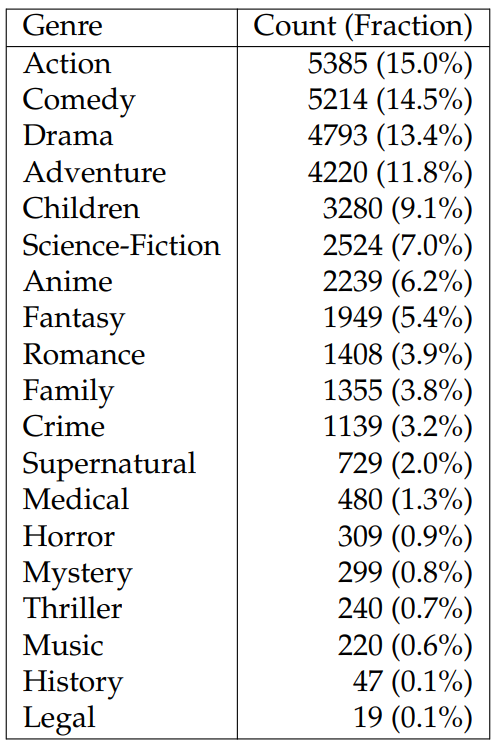
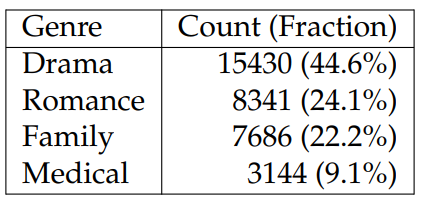
In Tables 6.25 and 6.26, we verify the diversity of topics covered in TVSTORYGEN, finding that FD covers far more genres than TMS with the most frequent occupying only 15% of episodes. We randomly split the datasets into train/dev/test sets. For TMS, we additionally filter out instances if the overlap ratio of TV show characters appearing in the summary and the detailed recap is lower than 85%. This extra filtering step ensures alignment between the summaries and detailed recaps. See Table 6.27 for the train/dev/test sizes for FD and TMS.
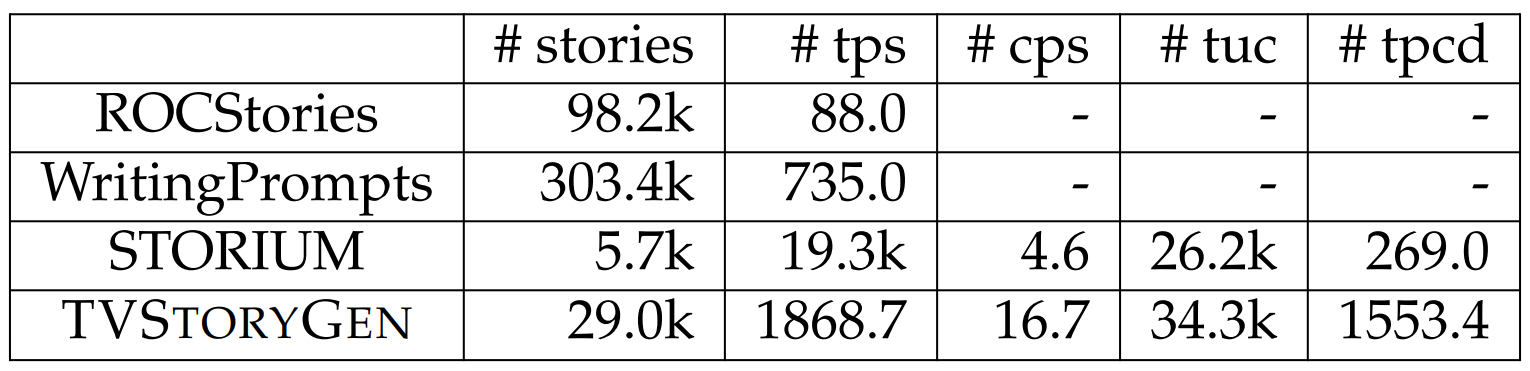
Dataset Comparison. We compare TVSTORYGEN to other story generation datasets in Table 6.23. Unlike ROCStories (Mostafazadeh et al., 2016) and WritingPrompts (Fan et al., 2018b) where the inputs to models are either the first few
sentences or short prompts, TVSTORYGEN has character descriptions as extra constraints, making the task of generating the reference stories from the inputs less open-ended and therefore more feasible.
Since STORIUM (Akoury et al., 2020) has character descriptions and other information as constraints, it is the most comparable resource to TVSTORYGEN. Below we compare our dataset to STORIUM in detail.
-
Our dataset has more stories, more characters, and longer character descriptions.
-
The stories in STORIUM often have detailed descriptions about environments and character utterances, whereas the stories in TVSTORYGEN mostly narrate events that happened without these details. While this leads to shorter stories in TVSTORYGEN, it also prevents the task from conflating generating events and generating other kinds of details in story generation.
-
Due to the fact that the plots in STORIUM are gamified and crafted by amateur writers, 89.8% of stories in STORIUM are unfinished.[24] The stories in our dataset are created and refined by professional screenwriters (though the prose is written by fans, who are presumably amateurs).
-
Stories in STORIUM are turn-based, where each turn is written from the perspective of a particular character and is composed by one player, so the stories often lack direct interactions among characters, unlike TVSTORYGEN.
-
Unlike other story generation datasets, there is an episodic structure among the stories in TVSTORYGEN, which can potentially be used to improve the modeling of characters.
-
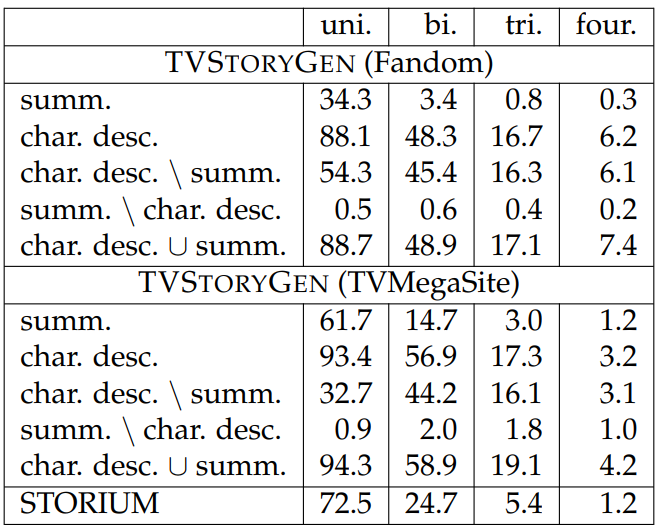
Source inputs and output stories are more closely related in TVSTORYGEN than STORIUM. To quantitatively illustrate the extent of relatedness between the source inputs and the output stories, we compute the n-gram overlap ratio (i.e., fraction of n-grams in the output stories that also appear in the source inputs) between the inputs and outputs where higher ratios indicate that the two are more directly related. When computing the results for STORIUM, we use the best setting, i.e., the setting that maximizes the automatic and human evaluation scores in the original paper. We report results in Table 6.28. From the table, we see that for both FD and TMS, using both character descriptions and summaries leads to an overlap ratio higher than STORIUM, suggesting that the reference stories are more reachable. Also, we observe there are more overlapping n-grams in the character descriptions than the summaries, suggesting that there is useful information that can be extracted from the character descriptions.
-
STORIUM lacks direction interactions among characters. We quantify this phenomenon in STORIUM by computing the frequency of occurrences of characters in each turn excluding the character that owns the turn, and the frequency is 0.8 on average with 50.4% of the turns absent such occurrences.[25] In contrast, TV shows advance plots by interactions among characters.
Moreover, models trained on TVSTORYGEN can potentially complement those from STORIUM by merging all the characters’ turns in STORIUM into a coherent narrative.
Summarization. By considering generating the brief summary from the detailed episode recap, we can view TVSTORYGEN as an abstractive summarization dataset, which we call TVSTORYSUM. We simply use the detailed episode recap as the source
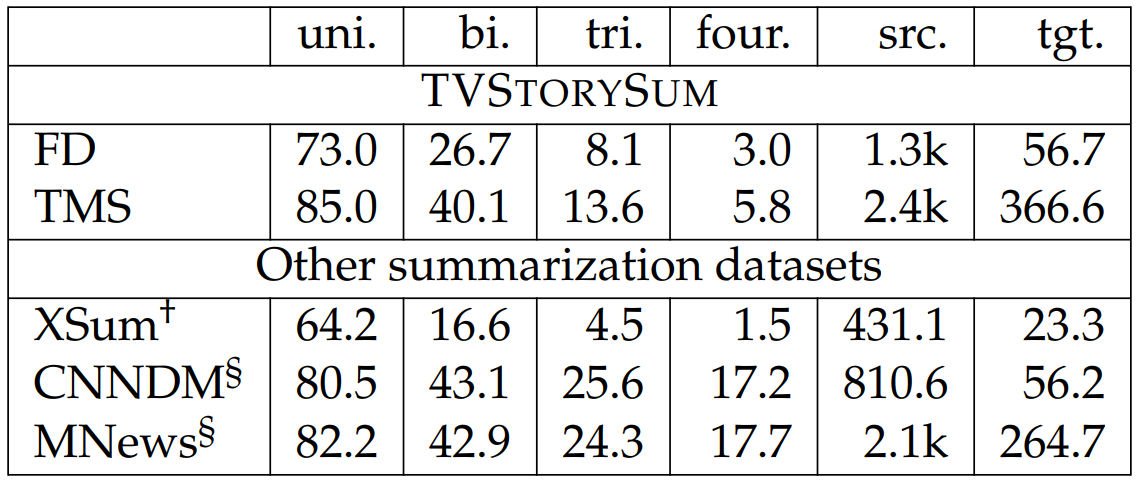
input and the summary as the target output and leave the integration of character descriptions to future work. We briefly compare TVSTORYSUM to three summarization datasets: CNNDM (Hermann et al., 2015), XSum (Narayan et al., 2018), and MNews (Fabbri et al., 2019). For TVSTORYSUM, we simply use the detailed episode recap as the source input and the summary as the target output and leave the integration of character descriptions to future work. We report n-gram overlap ratio (i.e., fraction of n-grams in the output stories that also appear in the source inputs) and length statistics in Table 6.30. The n-gram overlap ratio is usually used as an indicator of the abstractiveness of a summarization dataset. Lower ratio indicates a

higher degree of abstraction. CNNDM favors extractive approaches, whereas XSum is known for it is abstractiveness. We also compare to MNews because it shares similar input and output lengths as our dataset. As shown in the table, our dataset tends to be more abstractive. In addition, unlike other summarization datasets, our dataset focuses on stories. These two characteristics make our dataset a potentially valuable contribution for the summarization community. Comparison to other abstractive summarization datasets is in Table 6.29. The fact that TVSTORYSUM favors abstractive approaches and focuses on stories make it a potentially valuable contribution for the summarization community
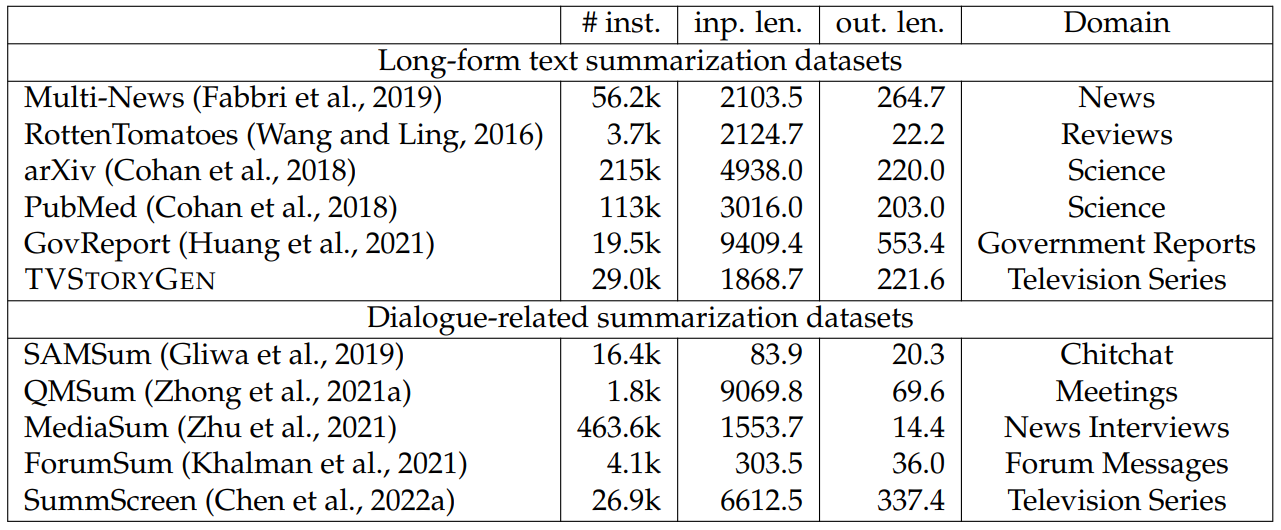
Dataset Challenges. TVSTORYGEN poses several challenges for story generation models. The first challenge stems from the long lengths of the inputs and outputs. Specifically, the average instance in TVSTORYGEN has a story of 1.8k tokens and character descriptions of more than 10k tokens (see Table 6.24). In contrast, story generation and multi-document summarization datasets may have lengthy inputs or outputs, but rarely both (see 6.23 and Section 6.3.3 for detailed statistics). The long inputs and outputs make it challenging to design models that can effectively integrate lengthy character descriptions into the generation process of long and coherent stories.
The other set of challenges relates to consistency in character modeling. Since the episode recaps are constrained by character descriptions, the dataset provides opportunities to evaluate neural models’ ability to maintain consistent personalities or goals of particular characters during generation. The consistency of personalities and goals is related to the notion of “character believability” (Bates et al., 1994; Riedl and Young, 2010), which has been deemed important for composing convincing stories. We illustrate this challenge with two excerpts in Table 6.31: the strong dislike that Selma has shown for Homer matches her description and is consistent across episodes. Solving this challenge requires models to first identify related information in the lengthy character descriptions based on the plot and integrate it into the generated narrative. We aim to incorporate this idea into the design of our models.
6.3.4 Method
We follow Fan et al. (2019b) to take a hierarchical story generation approach. The generation process is broken into two steps that use two separately parameterized models: a text-to-plot model and a plot-to-text model. The text-to-plot model first generates detailed plots based on the inputs, and then conditioned on the plots the plot-to-text model generates detailed stories. In this paper, we define the plots as linearized semantic role labeling (SRL) structures. More details on SRL are in the appendix. For example, a plot may be as follows:
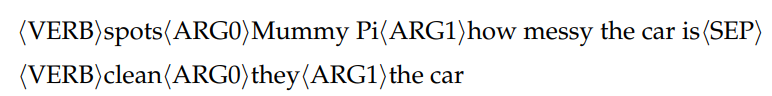
where h<SEP> is a special token used to separate SRL structures for different sentences.
Text-to-Plot Model. During training, we use the oracle plots, i.e., the SRL tags extracted from the reference recaps. During test time, we use BM25 to find the most similar plot in the training set from the same show based on either the summaries or the detailed recaps (as an oracle baseline).[26] If a show is not present in the training set, we search over the whole training set.
Plot-to-Text Model. Our models are based on the sequence-to-sequence transformer architecture (Vaswani et al., 2017). Similar to Rothe et al. (2020) that uses pretrained BERT-like models to initialize sequence-to-sequence models, we use the pretrained RoBERTa-base model (Liu et al., 2019) as the decoder.[27] For the encoder, we choose to use a one-layer randomly initialized Longformer (Beltagy et al., 2020) due to the lengthy inputs and computational constraints. We randomly initialize other parameters and finetune the whole model during training.
Given a plot, we use the neural models to generate sentence by sentence as we find this yields better performance than generating the whole detailed recap. When doing so, we concatenate the SRL tags for the adjacent sentence of the target sentence with the SRL tags for the target sentence. This gives similar performance to showing the SRL tags for the entire detailed recap but is much more efficient (due to shorter sequence lengths). Because the character descriptions are lengthy, we use BM25 to retrieve the most salient information from character descriptions (i.e., one sentence) for each sentence in the detailed recap. We note that during test time, when the textto-plot model retrieves plots from the training set, we also use the corresponding selected character descriptions.
The pipeline that retrieves relevant character information and then adapts it based on the plot is the first step that we take to simulate a writing system that can dynamically update its belief about particular characters based on the given relevant documents. This differs from prior work on entity representations for story generation (Clark et al., 2018) that does not consider character descriptions as we do.
The inputs to plot-to-text models contain two sources: plots and character descriptions. Since there could be multiple entries corresponding to different characters in the character descriptions, we include a type embedding to differentiate different entries and sources in the input. Similar approaches have been used to represent table entries in neural models (Dhingra et al., 2019; Herzig et al., 2020; Yin et al., 2020a). For example, for Fig. 6.6 the inputs are
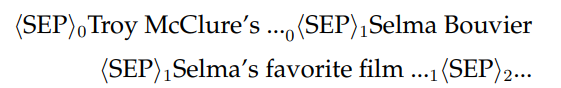
where the subscripts indicate the ID of the type embedding and we always prepend the character names to the corresponding selected character descriptions. The final vector representation of the input is the summation of subword unit embeddings, positional embeddings, and the type embeddings. Conditioned on the input representations, we train the RoBERTa decoder on the reference recaps using a crossentropy loss.
Due to computational constraints, for the Longformer encoder, we use the global attention on the <SEP> tokens, and use the encoded representations for the summary, the SRL tags, and the <SEP> tokens in character descriptions as the input to decoders.
6.3.5 Experiments
We perform experiments for both story generation and summarization.
Experimental Setup. For both story generation and summarization, we use a batch size of 200, beam search of size 5 with n-gram blocking where probabilities of repeated trigrams are set to 0 during beam search,[28] and report BLEU (BL), ROUGE1 (R1), ROUGE-2 (R2), and ROUGE-L (RL) scores. For story generation, we additionally report perplexities of the summaries given the generated stories using the summarization models. We will refer to this metric as “PL”. This metric evaluates the faithfulness of the generated stories to the summaries. Lower PL suggests better faithfulness. When computing PL, we use the Pegasus model Zhang et al. (2020a) finetuned on our dataset as it has the best test set perplexities. More details on hyperparameters are in the appendix. The dataset is available at https: //github.com/mingdachen/TVStoryGen.
Experimental Result. We report results for FD and TMS in Tables 6.32 and 6.33, respectively. We report several return-input baselines on the test sets to show the benefits of using neural models as plot-to-text models. We report PL on the test sets as an approximated lower bound of this metric. We do not report PL on return-input baselines as the output detailed recaps involve SRL sequences, which are not natural language, and therefore the results are not comparable to others.
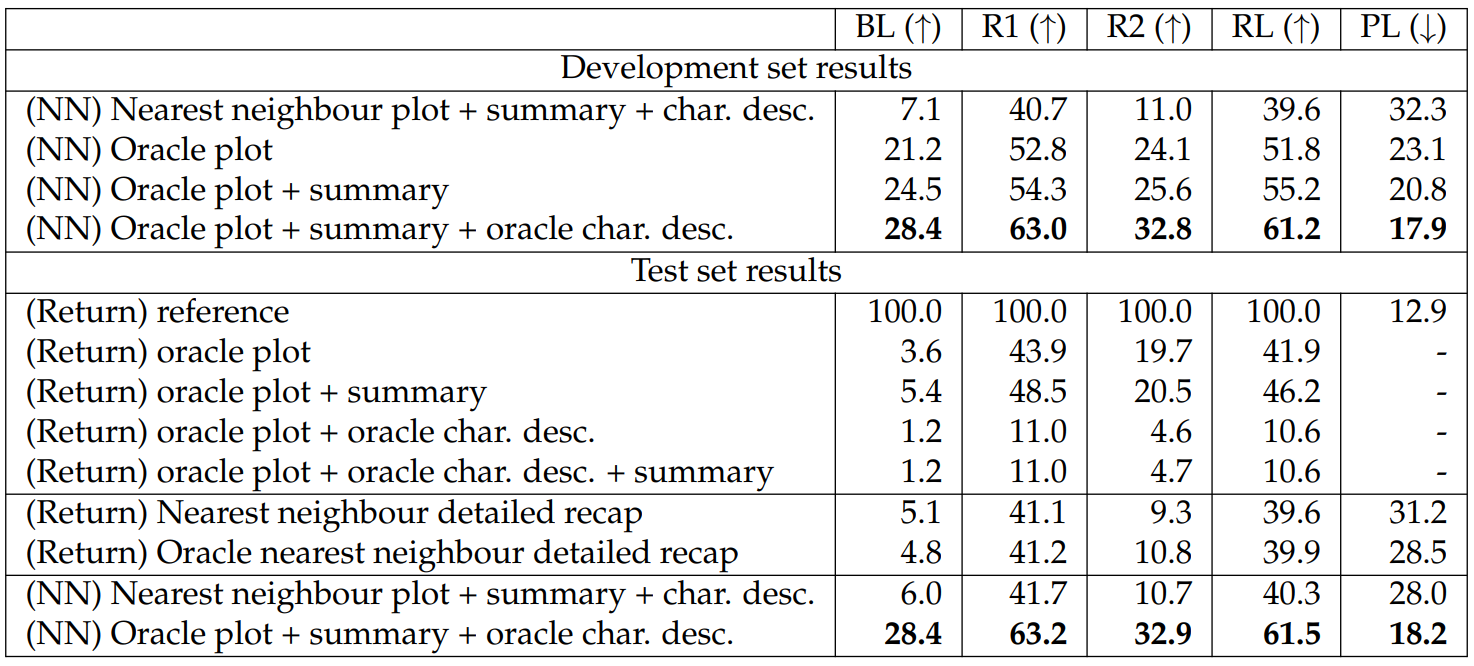
On the development sets, adding summaries and oracle character descriptions generally improves performance by a significant margin, showing that the extra information aids generation.
Regarding the test set results, we find that (1) the return-input baselines show that the performances of our neural models are non-trivial; (2) while the oracle nearest neighbour baselines achieve competitive performance to our non-oracle neural models, the non-oracle neural models are consistently better than the non-oracle baselines, showing promising results for future research on our datasets. We note that the return-input baselines involving character descriptions display much worse results than other return-input baselines because they are lengthy, which leads to low precision.
We report results in Table 6.34. We report the performance of an extractive oracle where for each sentence in the reference summary, we pick a sentence in the detailed episode recap that maximizes the average of the three ROUGE scores compared against the summary sentence. While recent pretrained models, such as Pegasus, have outperformed the oracle extractive approaches by a large margin on datasets with a high degree of abstractiveness (e.g., XSum (Narayan et al., 2018)), the results in the table show that our dataset is still challenging for these pretrained models.
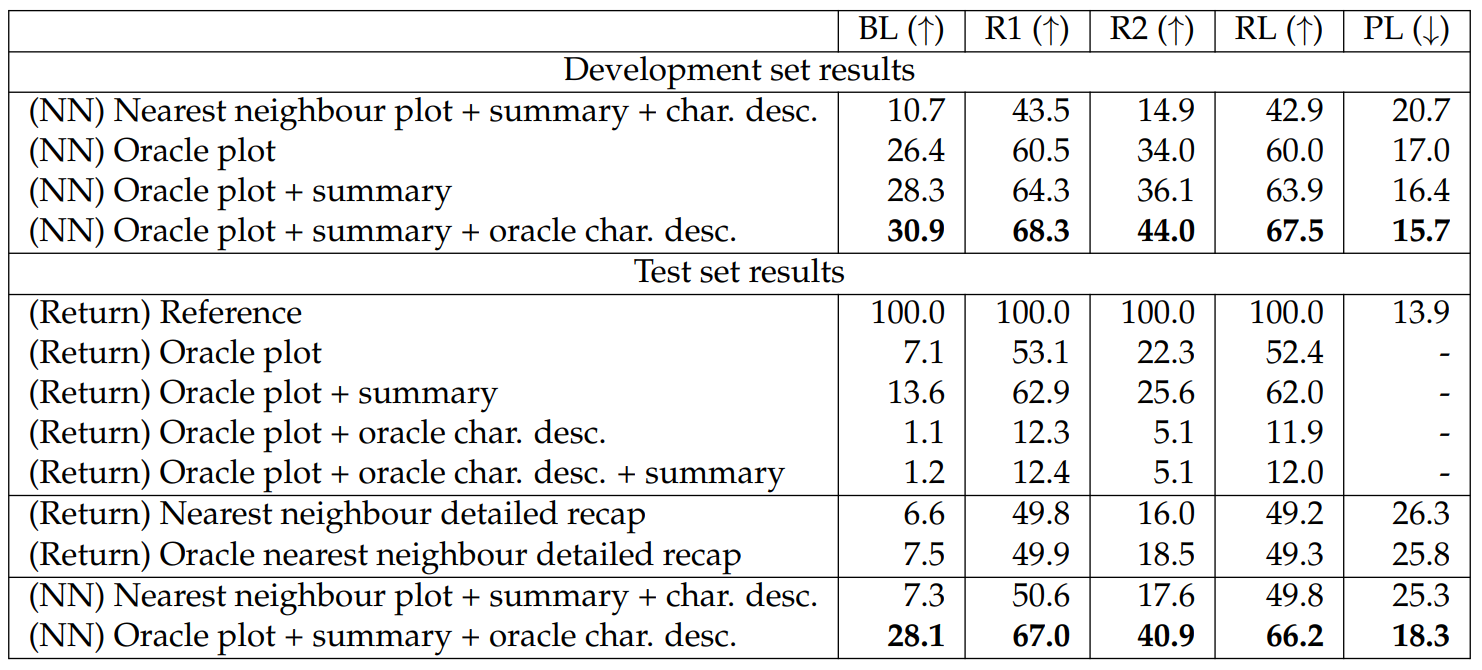
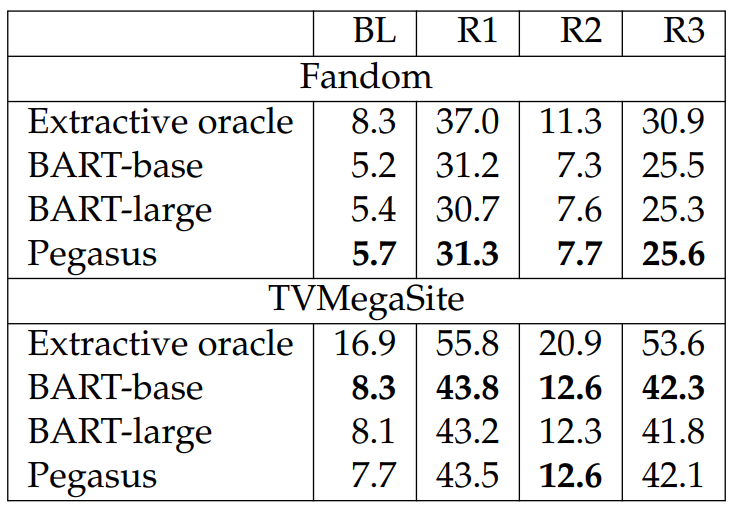
It is also interesting to see that while Pegasus is best for Fandom, it is not best on TVMegaSite. This may be because TVMegaSite has longer summaries than Fandom. Also, the performance of BART-base is comparable to that of BART-large on Fandom and is better than Pegasus and BART-large on TVMegaSite. This is likely because there is a limited amount of data with similar writing style in pretraining, resulting in little benefit of using larger models for this downstream task. We provide this abstractive summarization task to the community as a challenging dataset for future work.
6.3.6 Analysis
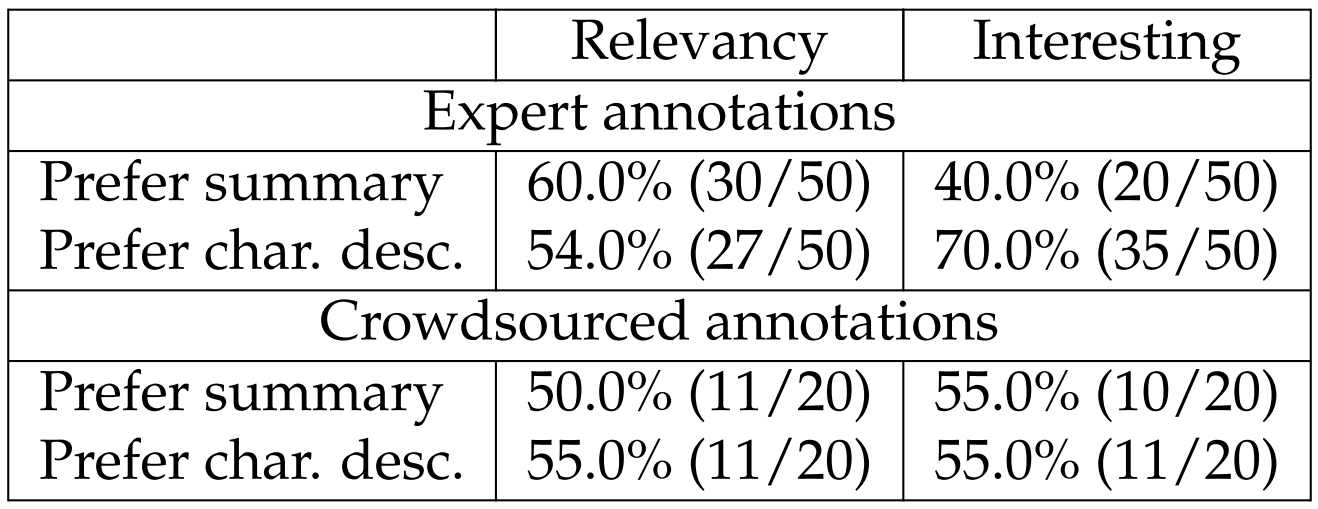
Human Evaluation. To measure the impact of including different components in TVSTORYGEN, we conduct a human evaluation. We show two generated stories from different models along with the corresponding brief summary and ask annotators to choose which story they prefer according to two aspects: (1) which generation is more relevant to the summary; (2) which story is more interesting.
We make two comparisons: “oracle plot” vs. “oracle plot+summary” for studying the benefits of using summaries (“Prefer summary”), and “oracle plot+summary” vs. “oracle plot+summary+oracle char. desc.” for studying the benefits of using character descriptions (“Prefer char. desc.”). We sample instances from the FD development set because the average lengths in FD are shorter, and we only show annotators the first 100 tokens of the texts as we expect it to be challenging to annotate lengthy texts. We use Amazon Mechanical Turk (AMT) and collect 20 annotations per question for each comparison with 6 workers involved (shown in Table 6.35 as “crowdsourced annotations”).[29] We (the authors) also annotate 50 instances per comparison using the same interface as AMT (shown in the table as “expert annotations”). While the crowdsourced annotations do not suggest clear benefits of using summaries and character descriptions, the expert annotations show that including the summary helps to improve relevancy but hurts the interestingness of the stories, whereas including character descriptions improves the interestingness
despite the marginal benefits of improving the relevancy. Recent work (Karpinska et al., 2021) also found that compared to experts, AMT workers produce lower quality annotations for tasks like story generation.
When examining annotations, we find that models without using character descriptions tend to generate sentences that use the word “but” to negate what has been said in the earlier part of the sentence, leaving the sentence dwelling on each event separately rather than advancing the plot (see Section 6.3.6 for examples). To quantify the observation that the models tend to generate sentences that use the word “but” to negate what has been said in the earlier part of the sentence, we compute the frequency of the word “but” per sentence for the reference stories, “oracle plot+summary”, and “oracle plot+summary+oracle char. desc.”. The results are 0.13, 0.53, and 0.24, respectively.
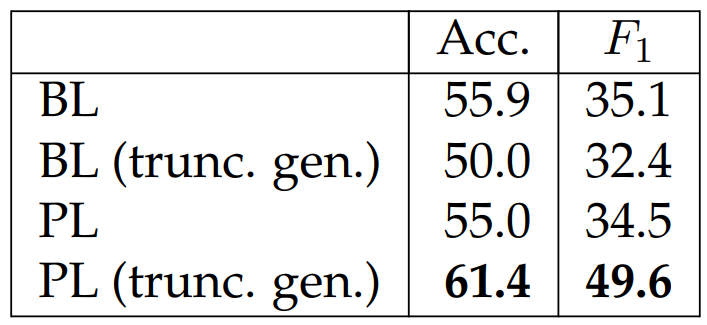
To verify the efficacy of our proposed metric PL, we compute accuracies and F1 scores between the PL metric and the human annotations (we use the expert relevancy annotations from both comparisons in human evaluation results). We consider BL as a baseline metric by computing the generation against the brief summaries. When reporting results for PL and BL, we consider two variants: one that uses the truncated generation and the other one that uses all the tokens in the generation. We show the results in Table 6.36. While PL and BL show similar performance in the non-truncated setting, we find that in the truncated setting PL outperforms BL significantly, showing that PL is a promising metric for evaluating the faithfulness of generated story. We speculate that the discrepancy is likely caused by the fact that the annotations were collected based on the truncated generations.
Generation Examples. We display the generation examples in Table 6.37 where we find that generations from both models generally share similar topics and character
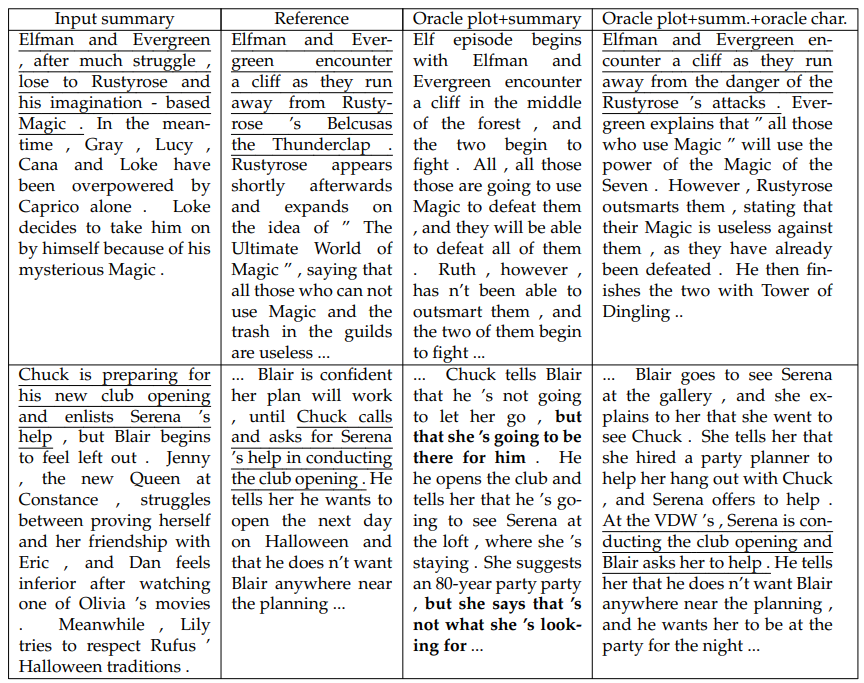
names with the summaries and the references. For example, for the first instance, both generations are about a battle that concerns Elfman, Evergreen, and Rustyrose. However, as observed in the human evaluations, the “oracle plot+summary” model suffers from meaningless negation. For example, see the second generation example, where the highlighted texts keep negating the earlier plot development. While the “Oracle plot+summ.+oracle char.” model does not have this problem, it is still not faithful to the summary. Specifically, both the summary and the reference mention that Chuck needs Serena’s help for his new club opening, but the generation states that “Serena is conducting the club opening” and “Blair asks her to help”. This is likely caused by the model’s inability to understand the states of each character (possibly due to the fact that our models generate at the sentence level) and to effectively integrate multiple sources of information into a coherent narrative.
This paper is available on arxiv under CC 4.0 license.
[20] https://www.fandom.com/
[21] http://tvmegasite.net/
[22] Data from Fandom is available under Creative Commons licenses and we have received permission from the owners of tvmegasite.net to publish their data for use with attribution.
[23] We sample 60 episodes with 2 episodes per show.
[24] We label a story as unfinished if it has no completion date.
[25] We use string matching to detect the occurrences of characters as in the way we construct our dataset.
[26] We find the plots generated by neural models to be of lower quality.
[27] We chose RoBERTa over GPT-2 (Radford et al., 2019) because BERT-style models outperform GPT2 in the encoder-decoder setting in the results reported by Liu et al. (2019).
[28] We did not find nucleus sampling (Holtzman et al., 2020) leading to better generation quality (i.e., fluency and faithfulness to the summaries and the recaps) than beam search with n-gram blocking, possibly due to the fact that our models generate at the sentence level.
[29] To ensure annotation quality, we hire workers with master qualification and pay them with a target hourly wage of $12.