
Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
6.1 Long-Form Data-to-Text Generation
6.1.1 Introduction
Data-to-text generation (Kukich, 1983; McKeown, 1992) is the task of generating text based on structured data. Most existing data-to-text datasets focus on singlesentence generation, such as WIKIBIO (Lebret et al., 2016), LogicNLG (Chen et al., 2020d), and ToTTo (Parikh et al., 2020). Other datasets are relatively small-scale and focus on long-form text generation, such as ROTOWIRE (Wiseman et al., 2017) and MLB (Puduppully et al., 2019). In this work, we cast generating Wikipedia sections as a data-to-text generation task and build a large-scale dataset targeting Mult sentence data-to-text generation with a variety of domains and data sources.
To this end, we create a dataset that we call WIKITABLET (“Wikipedia Tables to Text”) that pairs Wikipedia sections with their corresponding tabular data and various metadata. The data resources we consider are relevant either to entire Wikipedia articles, such as Wikipedia infoboxes and Wikidata tables, or to particular sections. Data from the latter category is built automatically from either naturally-occurring hyperlinks or from named entity recognizers. This data construction approach allows us to collect large quantities of instances while still ensuring the coverage of the information in the table. We also perform various types of filtering to ensure dataset quality.
WIKITABLET contains millions of instances covering a broad range of topics and a variety of flavors of generation with different levels of flexibility. Fig. 6.1 shows two examples from WIKITABLET. The first instance has more flexibility as it involves generating a fictional character biography in a comic book, whereas the second is more similar to standard data-to-text generation tasks, where the input tables contain all of the necessary information for generating the text. While the open-ended instances in WIKITABLET are to some extent similar to story generation (Propp, 1968; McIntyre and Lapata, 2009; Fan et al., 2018b), the fact that these instances are still constrained by the input tables enables different evaluation approaches and brings new challenges (i.e., being coherent and faithful to the input tables at the same time).
Because of the range of knowledge-backed generation instances in WIKITABLET, models trained on our dataset can be used in assistive writing technologies for a broad range of topics and types of knowledge. For example, technologies can aid students in essay writing by drawing from multiple kinds of factual sources. Moreover, WIKITABLET can be used as a pretraining dataset for other relatively smallscale data-to-text datasets (e.g., ROTOWIRE). A similar idea that uses data-to-text generation to create corpora for pretraining language models has shown promising results (Agarwal et al., 2021). In experiments, we train several baseline models on WIKITABLET and empirically compare training and decoding strategies. We find that the best training strategies still rely on enforcing hard constraints to avoid overly repetitive texts. Human evaluations reveal that (1) humans are unable to differentiate the human written texts from the generations from our neural models; (2) while the annotations show that grammatical errors in the reference texts and the generations may prevent humans from fully understanding the texts, the best decoding strategy (i.e., beam search with n-gram blocking (Paulus et al., 2018)) does not have such a problem and shows the best performance on several aspects; (3) the degree of topical similarity between the generations and the reference texts depends on the open-endedness of the instances.
Our analysis shows that the generations are fluent and generally have high quality, but the models sometimes struggle to generate coherent texts for all the involved entities, suggesting future research directions. For example, when the instance has a high degree of flexibility, we find the models making mistakes about what a particular entity type is capable of. We also find errors in terms of the factuality of the generated text, both in terms of contradictions relative to the tables and commonsense violations.
6.1.2 Related Work
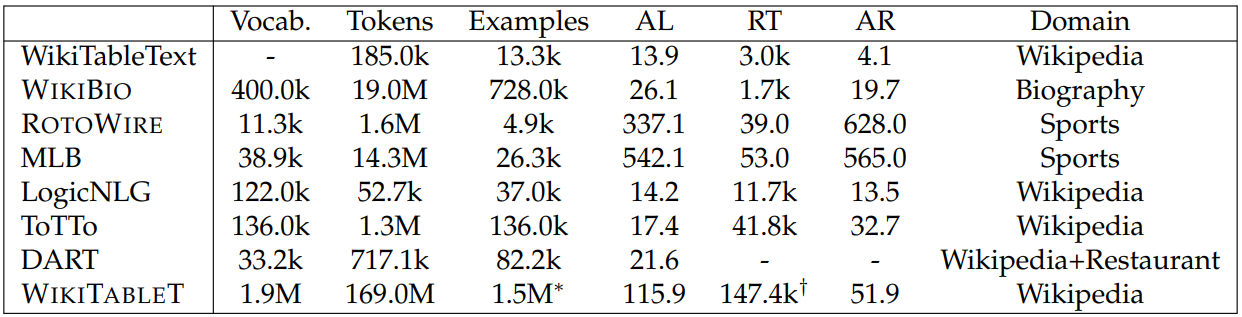
There have been efforts in creating data-to-text datasets from various resources, including sports summaries (Wiseman et al., 2017; Puduppully et al., 2019), weather forecasts (Liang et al., 2009), and commentaries (Chen and Mooney, 2008). Most of the recent datasets focus on generating single sentences given tables, such as WIKIBIO, ToTTo, LogicNLG, and WikiTableText (Bao et al., 2018b), or other types of data formats, such as data triples (Vougiouklis et al., 2018; Gardent et al., 2017; Nan et al., 2021), abstract meaning representations (Flanigan et al., 2016), minimal recursion semantics (Hajdik et al., 2019), or a set of concepts (Lin et al., 2020a). Other than single sentences, there have been efforts in generating groups of sentences describing humans and animals (Wang et al., 2018b), and generating a post-modifier phrase for a target sentence given a sentence context (Kang et al., 2019). In this work, our focus is long-form text generation and we are interested in automatically creating a large-scale dataset containing multiple types of data-to-text instances. As shown in Table 6.1, WIKITABLET differs from these datasets in that it is larger in scale and contains multi-sentence texts. More details are in the next section.
Wikipedia has also been used to construct datasets for other text generation tasks, such as generating Wikipedia movie plots (Orbach and Goldberg, 2020; Rashkin et al., 2020) and short Wikipedia event summaries (Gholipour Ghalandari et al., 2020), and summarizing Wikipedia documents (Zopf, 2018; Liu* et al., 2018) or summaries of aspects of interests (Hayashi et al., 2021) from relevant documents.
As part of this work involves finding aligned tables and text, it is related to prior work on aligning Wikipedia texts to knowledge bases (Elsahar et al., 2018; Logan et al., 2019).
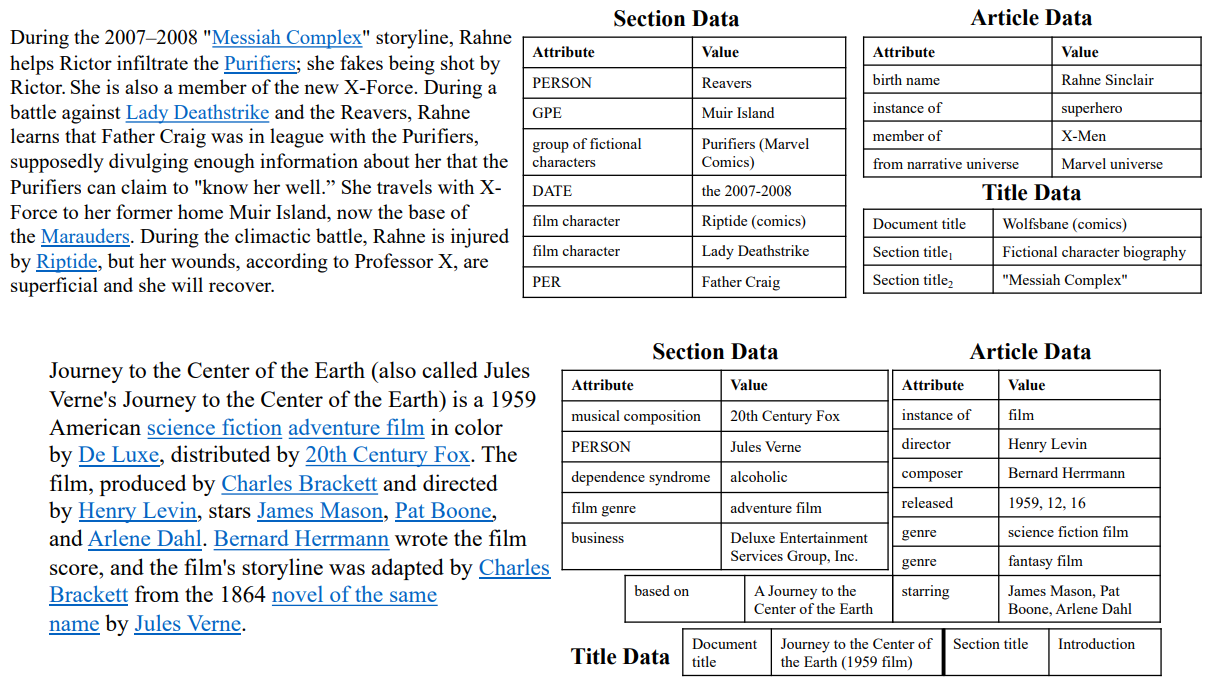
6.1.3 WIKITABLET
The WIKITABLET dataset pairs Wikipedia sections[1] with their corresponding tabular data and various metadata; some of this data is relevant to entire Wikipedia articles (“article data”) or article structure (“title data”), while some is section-specific (“section data”). Each data table consists of a set of records, each of which is a tuple containing an attribute and a value.
The instances in WIKITABLET cover a range of flavors of language generation. Some have more flexibility, requiring models to generate coherent stories based on the entities and knowledge given in the tables. The first instance in Fig. 6.1 is such an example. The text is from the Wikipedia article entitled “Wolfsbane (comics)” and resides within two nested sections: the higher-level section “Fictional character biography” and the lower-level section “Messiah Complex”. The task is challenging as models need to generate a coherent passage that can connect all the entities in the section data, and the story also needs to fit the background knowledge provided in the article data.
Other instances are more similar to standard data-to-text generation tasks, where the input tables contain all the necessary information for generating the text. The second instance in Fig. 6.1 is an example of this sort of task. However, these tasks are still challenging due to the wide variety of topics contained in WIKITABLET.
Dataset Construction. We begin by describing the steps we take to construct WIKITABLET. More details are in Appendix B.1. In general, the steps can be split into two parts: collecting data tables and filtering out texts. When collecting data, we consider five resources: Wikidata tables, infoboxes in Wikipedia pages,[2] hyperlinks in the passage, named entities in the passage obtained from named entity recognition (NER), and Wikipedia article structure. For a given Wikipedia article, we use the same infobox and Wikidata table for all sections. These tables can serve as background knowledge for the article. For each section in the article, we create a second table corresponding to section-specific data, i.e., section data. The section data contains records constructed from hyperlinks and entities identified by a named entity recognizer.[3]
We form records for named entities by using the type of the entity as the attribute and the identified entity as the value. We form records for hyperlinks as follows. For the attribute, for a hyperlink with surface text t and hyperlinked article `, we use the value of the “instance of” or “subclass of” tuple in the Wikidata table for `. For example, the first instance in Figure 6.1 will be turned into a record with attribute “superhero” and value “Wolfsbane (comics)”. If ` does not have a Wikidata table or no appropriate tuple, we consider the parent categories of `. For the value of the tuple, we use the document title of ` rather than the actual surface text t to avoid giving away too much information in the reference text.
Complementary to the article data, we create a title table that provides information about the position in which the section is situated, which includes the article title and the section titles for the target section. As the initial sections in Wikipedia articles do not have section titles, we use the section title “Introduction” for these.
We also perform various filtering to ensure the quality of the data records, the coverage of the input data, and the length of the reference text. The final dataset contains approximately 1.5 million instances. We randomly sample 4533 instances as the development set and 4351 as the test set. We also ensure that there are no overlapping Wikipedia articles among splits.
Dataset Characteristics. Table 6.1 shows statistics for WIKITABLET and related datasets. While the average length of a WIKITABLET instance is not longer than some of the existing datasets, WIKITABLET offers more diverse topics than the sportsrelated datasets ROTOWIRE and MLB, or the biography-related dataset WIKIBIO. Compared to the prior work that also uses Wikipedia for constructing datasets, WIKIBIO, LogicNLG, ToTTo, and DART (Nan et al., 2021) all focus on sentence generation, whereas WIKITABLET requires generating Wikipedia article sections, which are typically multiple sentences and therefore more challenging. WIKITABLET is also much larger than all existing datasets.
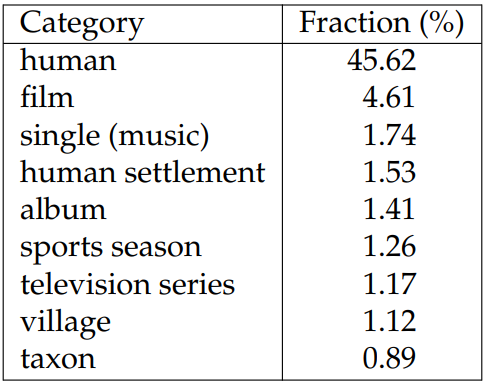
To demonstrate the diversity of topics covered in WIKITABLET, we use either the “instance of” or “subclass of” relation from Wikidata as the category of the article.[4] We show the top 10 most frequent document categories in Table 6.2. Due to the criteria we use for filtering, only 1.05% of articles in WIKITABLET do not have these relations or Wikidata entries, and we omit these articles in the table. As the table demonstrates, more than 50% of the articles in WIKITABLET are not about people (i.e., the topic of WIKIBIO), within which the most frequent category covers only 4.61%.
We highlight two challenges of WIKITABLET:
1. In contrast to work on evaluating commonsense knowledge in generation where reference texts are single sentences describing everyday scenes (Lin et al., 2020a), WIKITABLET can serve as a testbed for evaluating models’ abilities to use world knowledge for generating coherent long-form text.
2. Compared to other long-form data-to-text datasets such as ROTOWIRE where the input tables are box scores, the input tables in WIKITABLET are more diverse, including both numbers (e.g., economy and population data of an area throughout years), and short phrases. This makes WIKITABLET more challenging and applicable to various scenarios.
6.1.4 Method
In this section, we describe details of models that we will benchmark on WIKITABLET.
Our base model is based on the transformer (Vaswani et al., 2017). To encode tables, we linearize the tables by using special tokens to separate cells and using feature embeddings to represent records in tables. For the title table in the first instance in Fig. 6.1 the linearized table will be
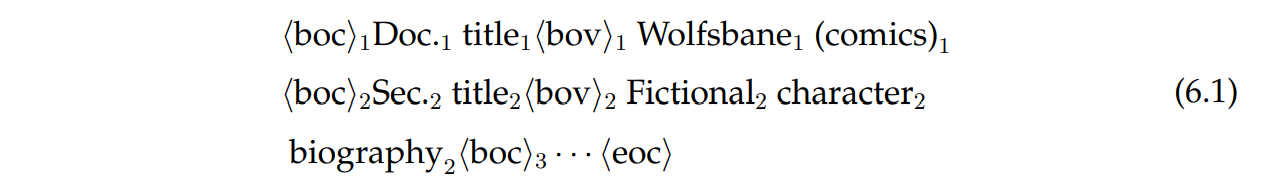
As shown in Eq. (6.1), we employ several techniques when encoding tables: (1) we use special tokens <boc> and ,bov> to separate attributes and values, and <eoc> to indicate the end of a sequence; (2) we use subscript indices to indicate unique ID embeddings that are added to the embeddings for each record, which helps models align attributes with values; and (3) we restart the positional embeddings at each,<boc>,, such that models will not use the ordering of the input records. In addition, we add a special embedding to each record to indicate if it is from the section table or the article/title table. In Wikidata, there could be multiple qualifiers attached to a record, in which case we replicate the record for each qualifier separately.
Similar linearization approaches have been used in prior work (Dhingra et al., 2019; Hwang et al., 2019; Herzig et al., 2020; Yin et al., 2020a). With linearized tables, training and inference become similar to other sequence-to-sequence settings. We train our models with teacher-forcing and standard cross entropy loss unless otherwise specified.
We experiment with three types of modifications to standard sequence-to-sequence training and a few decoding strategies:
α-entmax. α-entmax (Peters et al., 2019a) is a mapping from scores to a distribution that permits varying the level of sparsity in the distribution. This mapping function has been used in machine translation (Peters et al., 2019a) and text generation (Martins et al., 2020). When using α-entmax in the decoder, we also replace the cross entropy loss with the α-entmax loss (Peters et al., 2019a). Both α-entmax and the α-entmax loss have a hyperparameter α. We follow Martins et al. (2020) and use α = 1.2 as they found it to be the best value for reducing repetition in generation.
Copy Mechanism. Similar to prior work on data-to-text generation (Wiseman et al., 2017; Puduppully et al., 2019), we use pointer-generator network style copy attention (See et al., 2017) in the decoder.

this loss does not contain the generation model in it explicitly, but it does lead to an improved backward model by training it with clean inputs. Improving the backward model then increases the benefits of the cyclic loss.[5] The cyclic loss is used during training only and does not affect the models during inference.
Decoding Strategies. Massarelli et al. (2020) showed that the choice of decoding strategy can affect the faithfulness or repetitiveness of text generated by language models. We are also interested in these effects in the context of data-to-text generation, and therefore benchmark several decoding strategies on WIKITABLET. Our models use byte-pair encoding (BPE; Sennrich et al., 2016) and for all of the following strategies, we always set the minimum number of decoding steps to 100 as it improves most of the evaluation metrics, and the maximum number of decoding steps to 300. The details of the decoding algorithms we benchmark are as follows.
Greedy Decoding. In this setting, we feed the previous predicted tokens to the encoder, and then pick the word with the highest predicted probability as the prediction. This can be seen as a baseline strategy.
Nucleus Sampling. Generating long sequences usually suffers from repetitions. Nucleus sampling Holtzman et al. (2020) aims to reduce the repetitions in generations by sampling from truncated probability distributions. The truncation is based on whether the cumulative probability is above a threshold. We set the threshold to be 0.9 as suggested in Holtzman et al. (2020).
Beam Search. Beam search is a widely used deterministic decoding algorithm. It maintains a fixed size set of k candidate sequences. At each time step, it adds words from the vocabulary to these candidates, scores the new sequences, and then picks the ones with the top-k probabilities. We set the beam size k to be 5 by default.
Beam Search with n-gram Blocking. Paulus et al. (2018) found it effective to reduce the repetitions during beam search by “blocking” n-grams that have been generated in previous decoding steps. We follow their approach by using trigram blocking and setting the probability of repeated trigrams to be 0 during beam search.
Specifically, we benchmark (1) greedy decoding; (2) nucleus sampling (Holtzman et al., 2020) with threshold 0.9 as suggested by Holtzman et al. (2020); (3) beam search; and (4) beam search with n-gram blocking (Paulus et al., 2018) where we set the probabilities of repeated trigrams to be 0 during beam search. We set the beam size to be 5 by default.
6.1.5 Experiments
Setup. We experiment with two sizes of transformer models. One is “Base”, where we use a 1-layer encoder and a 6-layer decoder, each of which has 512 hidden size and 4 attention heads. The other one is “Large”, where we use a 1-layer encoder and a 12-layer decoder, each of which has 1024 hidden size and 8 attention heads. Models similar to the base configuration have shown strong performance on ROTOWIRE (Gong et al., 2019).[6] Due to limited computational power, we parameterize our backward model as a transformer model with a 2-layer encoder and a 2-layer decoder.[7]
We use BPE with 30k merging operations. We randomly sample 500k instances from the training set and train base models on them when exploring different training strategies. We train a large model with the best setting (using the copy mechanism and cyclic loss) on the full training set. We train both models for 5 epochs. During training we perform early stopping on the development set using greedy decoding.
We report BLEU, ROUGE-L (RL), METEOR (MET), and PARENT (Dhingra et al., 2019), including precision (PAR-P), recall (PAR-R), and F1 (PAR-F1) scores. The first three metrics consider the similarities between generated texts and references, whereas PARENT also considers the similarity between the generation and the table. When using PARENT, we use all three tables, i.e., the section, article, and title tables.
As we are also interested in the repetitiveness of generated texts, we define a metric based on n-gram repetitions which we call “REP”. REP computes the ratio of the number of repeated n-grams to the total number of n-grams within a text, so when REP has higher value, it indicates that the text has more repetitions. Here we consider n-grams that appear 3 or more times as repetitions and the n-grams we consider are from bigrams to 4-grams. When reporting REP scores for a dataset, we average the REP scores for each instance in the dataset. Similar metrics have been used in prior work (Holtzman et al., 2020; Welleck et al., 2020). Code and the dataset are available at https://github.com/mingdachen/WikiTableT.
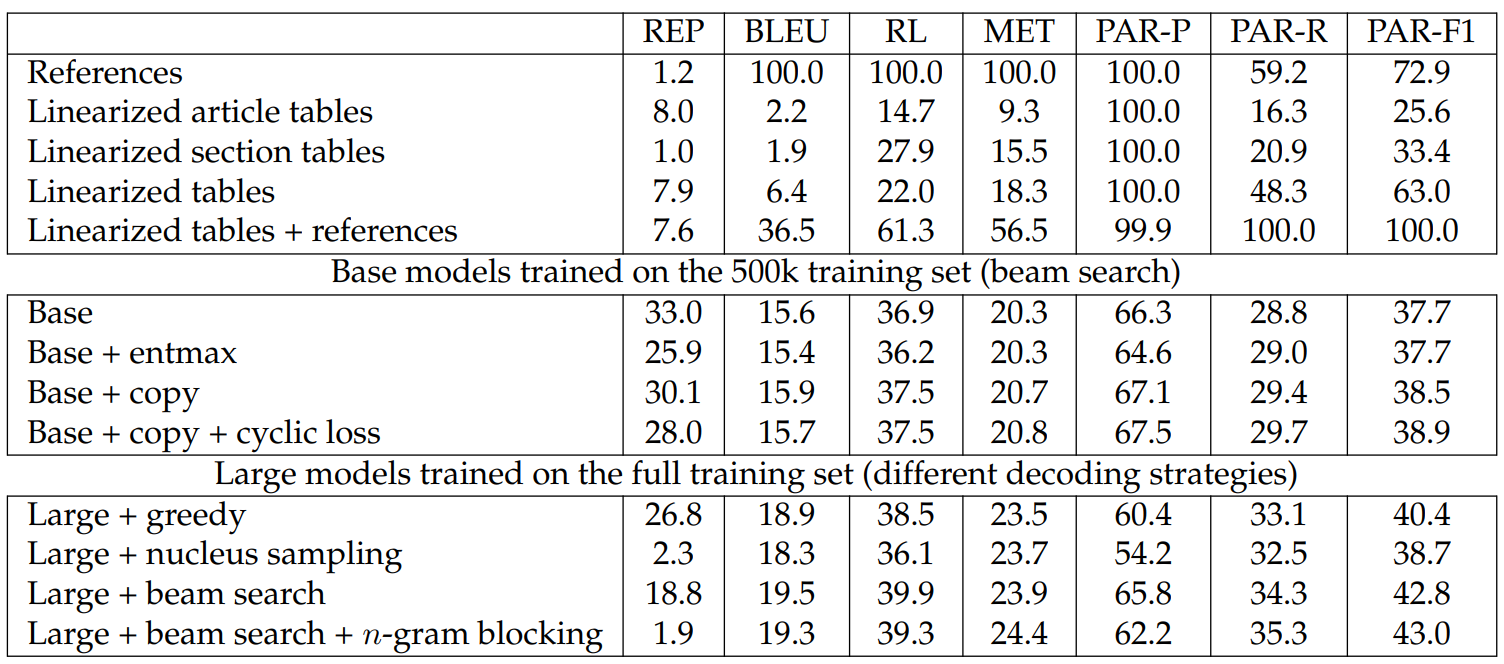
Results. In Table 6.3, we report the test results for both our base models and large models. We also report a set of baselines that are based on simply returning the linearized tables and their concatenations with the references. The linearized table baselines show how much information is already contained in the table, while the reference baselines show the upper bound performance for each metric.
In comparing training strategies, we find that using α-entmax improves REP significantly but not other metrics. Adding the cyclic loss or the copy mechanism helps improve performance for the PAR scores and REP, and combining both further improves these metrics.
When comparing decoding strategies, we find that both nucleus sampling and n-gram blocking are effective in reducing repetition. Nucleus sampling harms the PAR scores, especially PAR-P, but has less impact on the other metrics, indicating that it makes the model more likely to generate texts that are less relevant to the tables. Using beam search improves all metrics significantly when compared to greedy decoding, especially the PAR-P and REP scores. Adding n-gram blocking further reduces the REP score, pushing it to be even lower than that from nucleus sampling, but still retains the improvements in PAR scores from beam search. The best overall
decoding strategy appears to be beam search with n-gram blocking.
6.1.6 Analysis
We now describe a manual evaluation and analyze some generated examples. All results in this section use the development set.
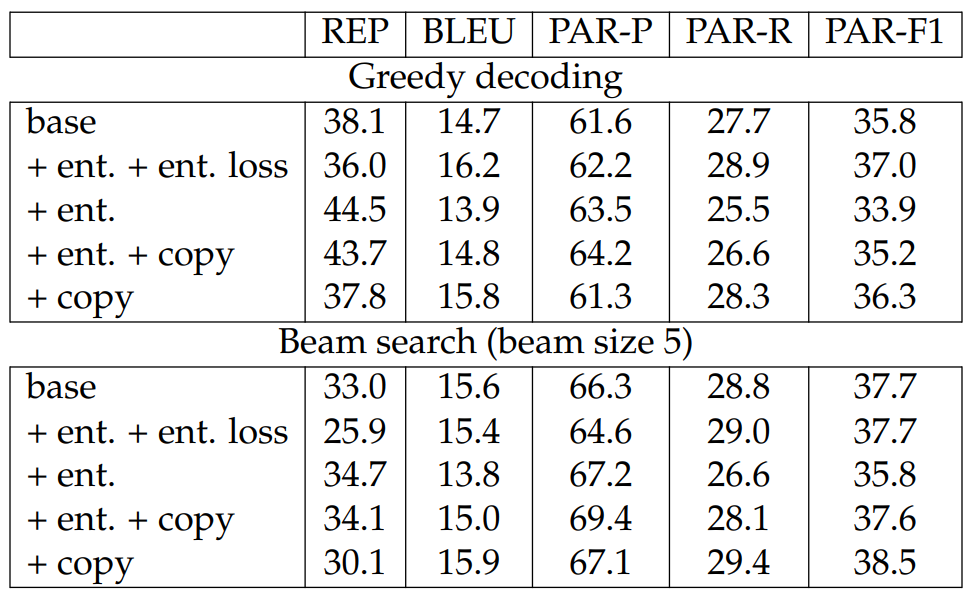
Effect of α-entmax. In this section, we disentangle the effect of α-entmax and that of α-entmax loss. We note that (1) when not using the α-entmax loss, we use standard cross entropy loss (e.g., in the case of “base+ent.” we maximize the log probabilities generated by α-entmax); (2) when combining α-entmax and copy mechanism, we aggregate the probabilities generated by α-entmax and those from softmax. This is because we use the first attention head in the transformer decoder as the copy attention, following the implementation in OpenNMT (Klein et al., 2017). While it is feasible to combine the α-entmax and α-entmax loss with the copy mechanism if we use the sparse transformer (Correia et al., 2019), we leave this for future study. We report the results in Table 6.4. It is interesting to see that when using greedy decoding, “ent. + ent. loss” outperforms the baseline model by a significant margin on all the metrics, however the improvement disappears (except for repetition) after we switch to use beam search as the decoding strategy. This is likely because α-entmax promotes sparsity in the generated probabilities, making beam search decoding unnecessary. Removing the α-entmax loss hurts the performance, but its gains become larger in switching to beam search decoding. Adding copy mechanism improves the performance, leading to comparable performance to the baseline model. Although “base+ent.+copy” still underperforms “base+copy” when using beam search, we believe that combining α-entmax and α-entmax loss with the copy mechanism is promising as (1) α-entmax is not used in our large models and the initial results have shown that α-entmax and the copy mechanism are complementary, so it may further improve our current best performance; (2) α-entmax already shows the best performance when using greedy decoding, which has speed and optimization advantages compared to the beam search based decoding strategies especially considering the long-form characteristic of WIKITABLET.
Human Evaluation. We conduct a human evaluation using generations from the large model on the development set. We choose texts shorter than 100 tokens and that cover particular topics as we found during pilot studies that annotators struggled with texts that were very long or about unfamiliar topics.[8]
We design two sets of questions. The first focuses on the text itself (i.e., grammaticality and coherence) and its faithfulness to the input article table. Since this set does not involve the reference, we can ask these questions about both generated texts and the reference texts themselves.
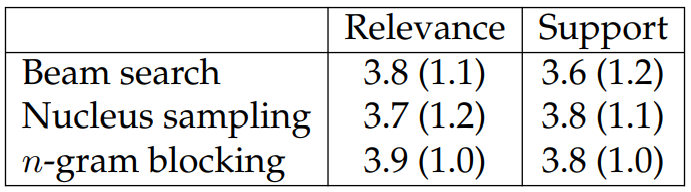
The second set of questions evaluates the differences between the generations and the reference texts (i.e., relevance and support), allowing us to see if the generated text matches the human written section text. Specifically, relevance evaluates topical similarity between generations and references, and support evaluates whether the facts expressed in the generations are supported by or contradictory to those in the references. The full questions and numerical answer descriptions are in Appendix B.2.
We report results in Tables 6.5 and 6.6. The scores are on a 1-5 scale with 5 being the best. For the first set, we collect 480 annotations from 38 annotators. For the second set, we collect 360 annotations from 28 annotators. We also ensure that each system has the same number of annotations.[9]
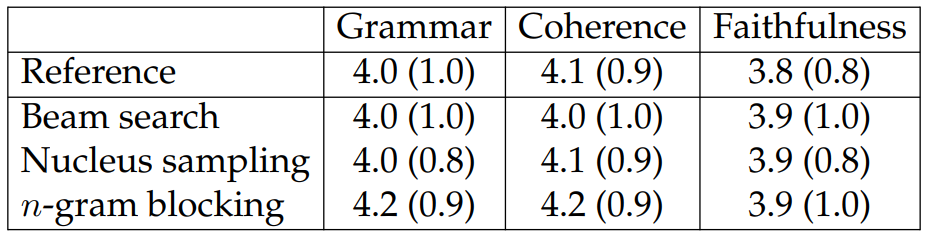
It is interesting to note from Table 6.5 that human annotators are unable to differentiate the human written texts from the generations from our neural models. Since the Wikipedia section texts are parts of Wikipedia articles, showing the section texts in isolation can make them difficult to understand, potentially resulting in noisy annotations. As shown by the first instance in Table 6.7, the text uses the pronoun “he” without clarifying what the pronoun refers to. The paragraph is rated 3 for coherence, presumably due to this ambiguity. Also, Wikipedia texts are sometimes grammatically complex and annotators can mistake them for being ungrammatical, e.g., the second instance in Table 6.7.
On the other hand, the coherence errors in the generated texts are not always easy to spot. See, for example, the last two instances in Table 6.7, where the incoherence lies in the facts that (1) it is impossible to marry a person before the person is born, and (2) senior year takes place after junior year. These details are embedded in long contexts, which may be overlooked by annotators and lead to results favorable to these neural models.
To study the relationship between coherence and grammaticality, we compute Spearman’s correlations between the human annotations for coherence and grammaticality after removing the ones with perfect scores for coherence. Table 6.8 shows


the results. The correlations are much higher for references, beam search, and nucleus sampling than for n-gram blocking. This trend suggests that the imperfect coherence scores for the reference texts are likely because annotators find the texts to contain grammatical errors (or to possess grammatical complexity) which may prevent them from fully understanding the texts. However, n-gram blocking does not have this problem and thus achieves the best results for both coherence and grammaticality. We hypothesize that n-gram blocking is able to avoid the types of grammatical errors that prevent understanding because (1) unlike nucleus sampling, n-gram blocking does not rely on randomness to avoid repetition; (2) n-gram blocking does not suffer from repetitions like beam search.
We report results for the second set of questions in Table 6.6. The three evaluated systems show similar performance. To investigate the relationship between the degree of open-endedness of a WIKITABLET instance and its corresponding evaluation scores, we compute the averaged perplexities (based on our large models) for each
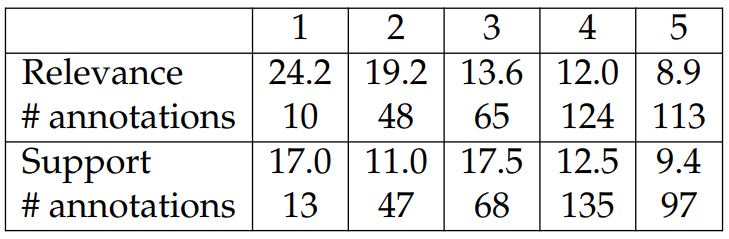
option in Table 6.9. The most relevant generations are typically from more closed-ended or constrained instances.[10] Similarly for the support scores, more open-ended instances are distributed at score 3, which means that there is no fact supported by or contradictory to the shown tables. While the open-endedness of an instance usually depends on its topics (e.g., movie plots are open-ended), there are many cases where the models can benefit from better entity modeling, such as understanding what a particular entity type is capable of (e.g., see the last example in Section 6.1.6).
Recent work has also found conducting human evaluation for long-form generation to be challenging, for example in the context of question answering (Krishna et al., 2021a) and story generation (Akoury et al., 2020). Our observations for data-totext generation complement theirs and we hope that our dataset can inspire future research on human evaluation for long-form text generation.
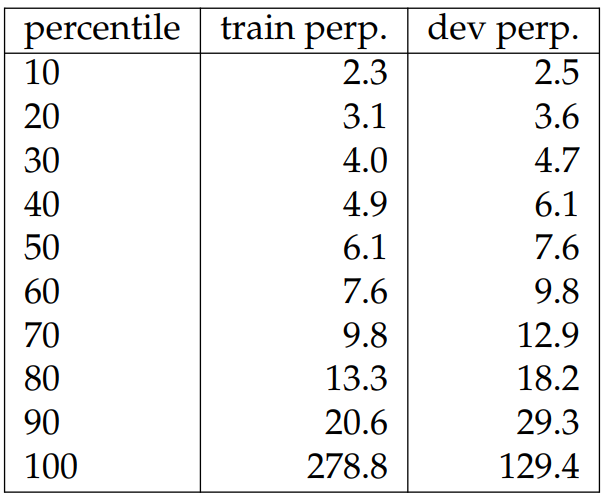
Distribution of Perplexity. To determine the fraction of WIKITABLET that can be seen as constrained, we report the percentiles of perplexities for training and development splits in Table 6.10. From Table 6.9, it can be observed that instances with perplexities around 9.0 generally lead to model generations that are closely relevant to the reference texts and mostly supported by the input tables, and therefore are likely to be the constrained instances. From Table 6.10, we see that at least half of our dataset has perplexities lower than 9.0, so we conjecture that half of our dataset consists of constrained instances.
Generation Examples. Table 6.11 shows generation examples for nucleus sampling and beam search with n-gram blocking. We observe very different trends between the two instances in Fig. 6.1. For the first instance about the X-Men, although both generations look fluent, their stories differ dramatically. The generated text for nucleus sampling describes a story that starts by saying Father Craig rescues the world from Reavers and ends with Wolfsbane joining as one of the new X-Men. On the other hand, n-gram blocking generates a story where Wolfsbane already is a member of X-Men, and the story says Father Craig fought and was killed by the Reavers, but manages to rescue the mutant. For the less open-ended instances (e.g., the second instance in Fig. 6.1), different decoding strategies mostly generate similar details.
Despite having different details, these generations appear to try to fit in as many entities from the tables as possible, in contrast to beam search which mostly degenerates into repetition for more open-ended instances. This explains our previous observation that n-gram blocking helps with the PAR-R score.
Even though the generations are of good quality for most instances, their implausibility becomes more apparent when readers have enough background knowledge to understand the involved entities. For example, the second instance in Table 6.11 comes from the Wikipedia page “LeSean McCoy” (a football player) under the sections “Personal life” and “Controversies”. The generation from nucleus sampling is implausible/nonsensical in some places (“assault a Spoiler business official”) and factually incorrect elsewhere (McCoy did not play a leading role in any film, and “Erab of the Press” is not an actual film). The fourth generation is implausible be
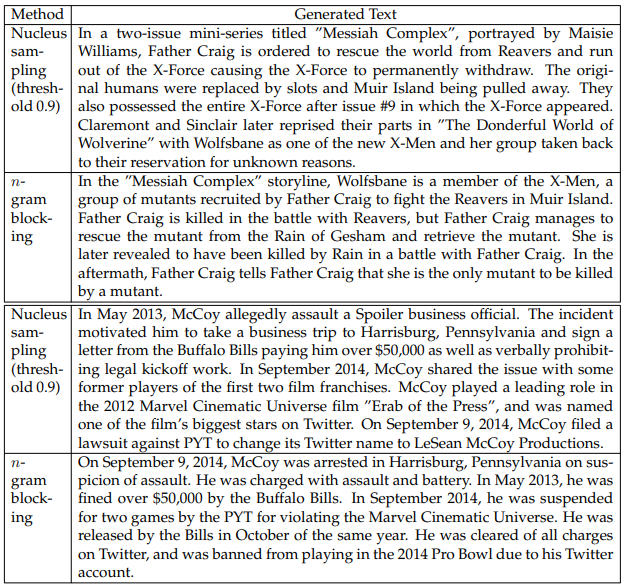
cause a player is unlikely to be suspended for “violating the Marvel Cinematic Universe”, and it is unlikely for a person to be cleared of all charges on Twitter. Our models have limited access to knowledge about entities, e.g., the capabilities of a social media company like Twitter. Future research may incorporate extra resources, make use of pretrained models, or incorporate factuality modules to solve these problems.
This paper is available on arxiv under CC 4.0 license.
[1] We define a Wikipedia section to be all text starting after a (sub)section heading and proceeding until the next (sub)section heading. We include Wikipedia sections at various nesting levels. For example, a top-level section may start with a few paragraphs describing general information followed by two subsections with more specific information, in which case the example will be converted into three instances in our dataset.
[2] Wikidata is a consistently structured knowledge base (e.g., has a fixed set of attributes), whereas infoboxes are not consistently structured and this flexibility sometimes allows the infobox to contain extra information. Therefore, we consider using infoboxes as extra resources.
[3] We use the NER tagger from spaCy (Honnibal and Montani, 2017) and a BERT model (Devlin et al., 2019) finetuned on CoNLL03 data (Tjong Kim Sang and De Meulder, 2003).
[4] When there are multiple values in these two relations, we pick the one that has the smallest number of words, as it often is the most generic phrase, suitable for representing the topic.
[5] We experimented with initializing the backward model with pretrained checkpoints, but did not find it helpful.
[6] When training the base model with entmax on WIKIBIO, it achieves BLEU-4 45.75 and ROUGE4 39.39 on the test set using greedy decoding, which are comparable to the current state-of-the-art results of Liu et al. (2018).
[7] We did not experiment with pretrained models because they typically use the entirety of Wikipedia, which would presumably overlap with our test set.
[8] We did not find the filtering to change the observed trends for the automatic metrics and provide the list of selected topics in Appendix B.2.
[9] We used Amazon Mechanical Turk. To ensure annotation quality, we only recruited annotators with master qualification. We collected one annotation for each instance (so that we can cover more instances) and paid 30 cents per annotation. The amount of wage per annotation is decided by (1) the amount of time each annotator spent on the task during our pilot study and (2) a target hourly wage of approximately $11.
[10] Li and Hovy (2015) use entropy as a proxy to quantify complexity of tasks. In this work, we use perplexity to measure how open-ended the instances are.