
Authors:
(1) Juan F. Montesinos, Department of Information and Communications Technologies Universitat Pompeu Fabra, Barcelona, Spain {juanfelipe.montesinos@upf.edu};
(2) Olga Slizovskaia, Department of Information and Communications Technologies Universitat Pompeu Fabra, Barcelona, Spain {olga.slizovskaia@upf.edu};
(3) Gloria Haro, Department of Information and Communications Technologies Universitat Pompeu Fabra, Barcelona, Spain {gloria.haro@upf.edu}.
Table of Links
IV. EXPERIMENTS
In order to show the suitability of Solos, we have focused in the blind source separation problem and have trained The Sound of Pixels (SoP) [23] and the Multi-head U-Net (MHUNet) [34] models on the new dataset. We have carried out four experiments: i) we have evaluated the SoP pre-trained model provided by the authors; ii) we have trained SoP from scratch; iii) we have fine-tuned SoP on Solos starting from the weights of the pre-trained model on MUSIC and iv) we have trained the Multi-head U-Net from scratch. MHU-Net has been trained to separate mixtures with the number of sources varied from two to seven following a curriculum learning procedure as it improves the results. SoP has been trained according to the optimal strategy described in [23].
Evaluation is performed on the URMP dataset [1] using the real mixtures they provide. URMP tracks are sequentially split in 6s-duration segments. Metrics are obtained from all the resulting splits.
A. Architectures and training details
We have chosen The Sound of Pixels as baseline since its weights are publicly available and the network is trained in a straight-forward way. SoP is composed of three main subnetworks: A dilated ResNet [35] as video-analysis network, a U-Net [36] as audio-processing network and an audio synthesizer network. We also compare its results against a Multi-head U-Net [34].
U-Net [37] is an encoder-decoder architecture with skip connections in between. Skip connections help to recover the original spatial structure. MHU-Net is a step forward as it consist of as many decoders as possible sources. Each decoder is specialized in a single source, thus improving performance.
The Sound of Pixels [23] does not follow the original UNet architecture proposed for biomedical imaging, but the UNet described at [36], which was tuned for singing voice separation. Instead of having two convolutions per block followed by max-pooling, they use a single convolution with
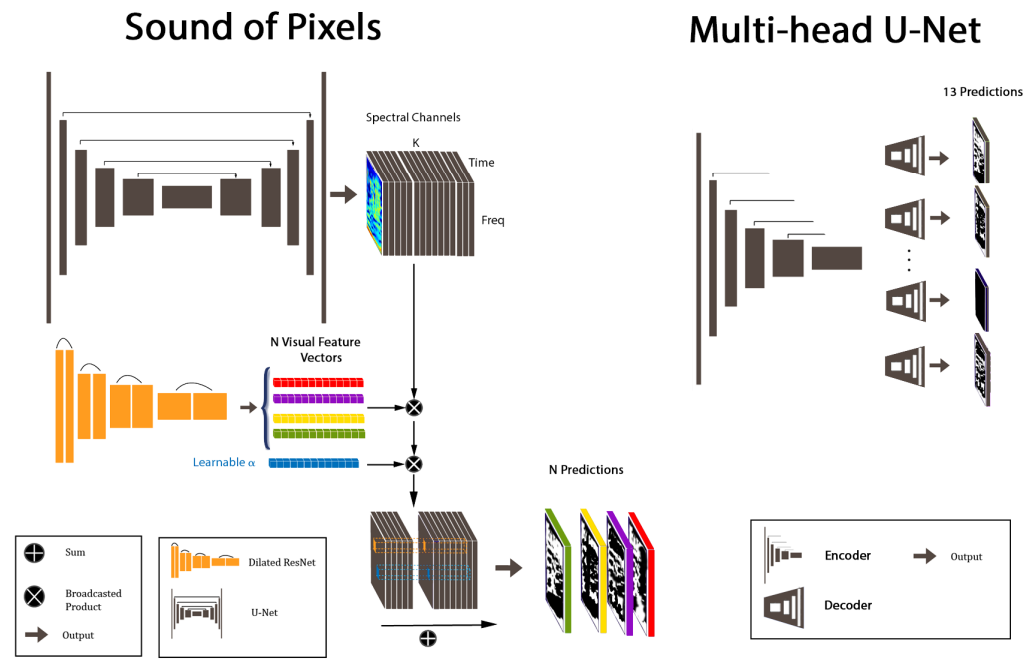
a bigger kernel and striding. The original work proposes a central block with learnable parameters whereas the central block is a static latent space in SoP. U-Net has been widely used as backbone of several architectures for tasks such us image generation [38], noise suppression and super-resolution [39], image-to-image translation [40], image segmentation [37] or audio source separation [36]. SoP U-Net consists of 7 blocks with 32, 64, 128, 256, 512, 512 and 512 channels respectively (6 blocks for the MHU-Net). The latent space can be considered as the last output of the encoder. Dilated ResNet is a ResNet-like architecture which makes use of dilated convolutions to keep the receptive field while increasing the resulting spatial resolution. The output of the U-Net is a set of 32 spectral components (channels) which are the same size than the input spectrogram, in case of SoP, and a single source per decoder in case of MHU-Net. Given a representative frame, visual features are obtained using the Dilated ResNet. These visual features are nothing but a vector of 32 elements (which corresponds to the number of output channels of UNet) which are used to select proper spectral components. This selection is performed by the audio analysis network which consist of 32 learnable parameters, αk, plus a bias, β. This operation can be mathematically described as follows:
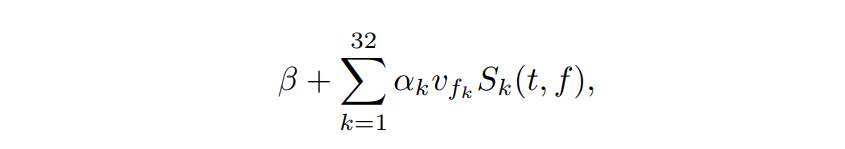
where Sk(t, f) is the k-th predicted spectral component at time-frequency bin (t, f).
Figure 2 illustrates the SoP configuration. It is interesting to highlight that making the visual network to select the spectral components forces it to indirectly learn instrument localization, which can be inferred via activation maps.


Ground-truth mask calculation for both SoP and MHU-Net are described in Eq. (2) and Eq. (3), Sec. IV-C.
B. Data pre-processing
In order to train the aforementioned architectures, audio is re-sampled to 11025 Hz and 16 bit. Samples fed into the network are 6s duration. We use Short-time Fourier Transform (STFT) to obtain time-frequency representations of waveforms. Following [23], STFT is computed using Hanning window of length 1022 and hop length 256 so that we obtain a spectrogram of size 512×256 for a 6s sample. Later on, we apply a log re-scale on the frequency axis expanding lower frequencies and compressing higher ones. Lastly, we convert magnitude spectrograms into dB w.r.t. the minimum value of each spectrogram and normalize between -1 and 1.
C. Ground-truth mask
Before introducing ground-truth mask computations we would like to point out some considerations. Standard floatingpoint audio format imposes a waveform to be bounded between -1 and 1. At the time of creating artificial mixtures resulting waveforms may be out of these bounds. This can help neural networks to find shortcuts to overfit. To avoid this behaviour spectrograms are clamped according to the equivalent bounds in the time-frequency domain.
The Discrete Short-time Fourier Transform can be computed as described in [42]:

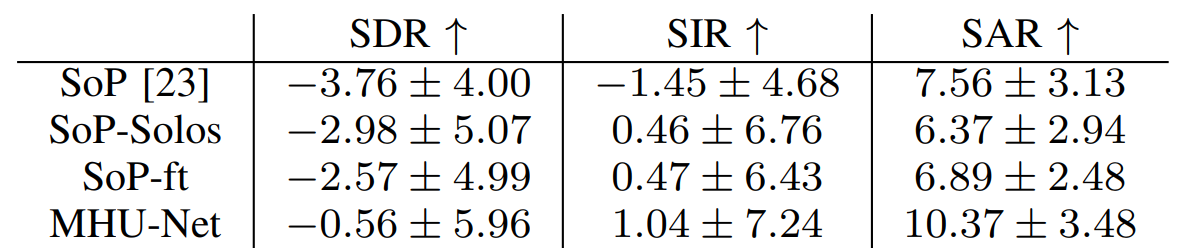
For training Sound of Pixels we have used complementary binary masks as ground-truth masks, defined as:
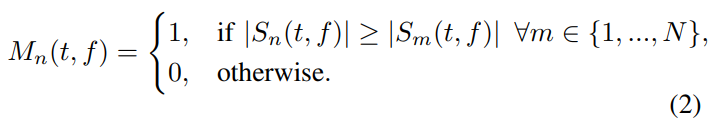
The Multi-head U-Net has been trained with complementary ratio masks, defined as:
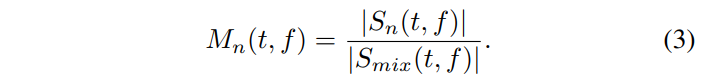
D. Results
Benchmark results for Source to Distortion Ratio (SDR), Source to Interferences Ratio (SIR), Sources to Artifacts Ratio (SAR) proposed in [43] are shown in Table II in terms of mean and standard deviation. As it can be observed, Sound of Pixels evaluated using its original weights performs the worst. One possible reason for that could be the absence of some of the URMP categories on the MUSIC dataset. If we train the network from scratch on Solos, results improve by almost 1 dB. However, it is possible to achieve an even better result fine-tuning the network, pre-trained with MUSIC, on Solos. We hypothesize that the improvement occurs as the network is exposed to much more training data. Moreover, the table results show how it is possible to reach higher performance by using more powerful architectures like MHU-Net.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.