
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Cristina España-Bonet, DFKI GmbH, Saarland Informatics Campus.
Table of Links
- Abstract and Intro
- Corpora Compilation
- Political Stance Classification
- Summary and Conclusions
- Limitations and Ethics Statement
- Acknowledgments and References
- A. Newspapers in OSCAR 22.01
- B. Topics
- C. Distribution of Topics per Newspaper
- D. Subjects for the ChatGPT and Bard Article Generation
- E. Stance Classification at Article Level
- F. Training Details
F. Training Details
F.1 L/R Classifier
We finetune XLM-RoBERTa large (Conneau et al., 2020) for L vs. R classification as schematised in Figure 1. Our classifier is a small network on top of RoBERTa that first performs dropout with probability 0.1 on RoBERTa’s [CLS] token, followed by a linear layer and a tanh. We pass trough another dropout layer with probability 0.1 and a final linear layer projects into the two classes. The whole architecture is finetuned.

We use a cross-entropy loss, AdamW optimiser and a learning rate that decreases linearly. We tune the batch size, the learning rate, warmup period and the number of epochs. The best values per language and model are summarised in Table 12.
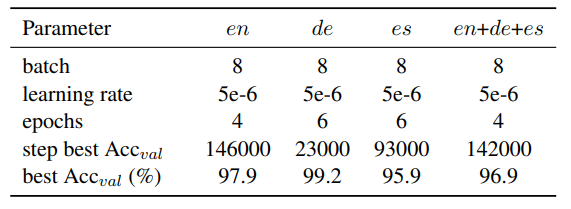
All trainings are performed using a single NVIDIA Tesla V100 Volta GPU with 32GB.
F.2 Topic Modelling
We use Mallet (McCallum, 2002) to perform LDA on the corpus after removing the stopwords, with the hyperparameter optimization option activated and done every 10 iterations. Other parameters are the defaults. We do a run per language with 10 topics and another run with 15 topics. We tag the corpus with both labels.