
Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
CHAPTER 2 - BACKGROUND
In this chapter, we present background on self-supervised pretraining, naturally occurring data structures, and variational models in the context of NLP.
2.1 Self-Supervised Language Pretraining
Self-supervised learning in NLP seeks to adapt plain text (without using extra information obtained via human annotations, e.g., labels, regardless of whether these annotations are naturally-occurring or not) for training models. Common training objectives in this area are word prediction based on nearby context, with language modeling being the dominant approach. The resulting models can either produce vector representations for words/sentences/documents or directly generate text. In practice, models typically “pretrain” on a massive amount of unlabeled textual data using the self-supervised learning objectives before being applied to downstream tasks.[1] As the models can transfer the knowledge learned during pretraining to downstream tasks and thus improve model performance, pretraining has gained increasing attention in recent years. Below we briefly review the advancement of this research area.
2.1.1 Related Work
Word Representations. Learning vector representations of words builds upon the distributional hypothesis (Harris, 1954): You shall know a word by the company it keeps (Firth, 1957). Based on this hypothesis, early methods attempt to learn a fixed set of vectors for word representations. Before the advent of neural models, researchers mostly used corpus-based cooccurrence statistics (Deerwester et al., 1990; Schutze ¨ , 1992; Brown et al., 1992; Lund and Burgess, 1996). These word vectors have been found to be helpful for intrinsic evaluation tasks (e.g., word similarities (Rubenstein and Goodenough, 1965; Miller and Charles, 1991) and analogies (Turney and Littman, 2005; Turney, 2006)) and for various NLP applications as features (e.g., named entity recognition (Miller et al., 2004) and semantic role labeling (Erk, 2007)).
With neural models, most training objectives shifted towards word predictions based on a limited context window from the corpus-level statistical information (Bengio et al., 2003; Collobert and Weston, 2008; Collobert et al., 2011). At this point, the word representations are typically within 100 dimensions and learned from corpora of a few million word tokens. Word2vec (Mikolov et al., 2013a) shows that scaling the size of training corpus to billions of word tokens and enlarging the dimensionality of word representations at the same time improve the quality of word representations. Later, GloVe embedding (Pennington et al., 2014) combines the corpus-based methods and the context window methods. Fasttext (Bojanowski et al., 2017) replaces word types in Word2vec with character n-grams. While considerable research interests continue to evaluate these vectors on traditional word-level tasks (e.g., word similarities), they became increasingly popular in getting applied to downstream tasks. The common practice became to use pretrained word vectors to initialize the word embedding layer in neural models (e.g., long short-term memory network (Hochreiter and Schmidhuber, 1997)) with optional gradient updates on the embedding layer (Collobert and Weston, 2008; Turian et al., 2010, inter alia).
Sentence Representations. One drawback of pretrained word vectors is that it represents each word in isolation, leading to challenges in designing higher-level (i.e., sentences[2]) representations that capture compositionality among low-level (i.e., words) units. One way to obtain sentence representations is deriving them from word vectors. In particular, researchers have using tried parse trees (Socher et al., 2013) and simple pooling operations (e.g., averaging) (Iyyer et al., 2015; Shen et al., 2018a). The effectiveness of the latter approach raises concerns that the neural models on top of the word embedding layers do not encode meaningful compositional semantics of words.
Pretrained word representations also inspired a series of research on pretraining sentence encoders. In contrast to most work on word representations which can only represent seen words in training data, sentence representations are neural models that encode any sentence into a fixed-length vector. In particular, Paragraph Vector (Le and Mikolov, 2014) averages or concatenates the words in input text and it is trained to predict next words. Skip-thought (Kiros et al., 2015) is a gated recurrent neural network (GRU; Cho et al., 2014; Chung et al., 2014) that is trained to predict the previous sentence and next sentence given the input one. Dai and Le (2015) use a LSTM-based sequence-to-sequence (Sutskever et al., 2014) autoencoder. FastSent (Hill et al., 2016) follows Skip-thought but simplifies the GRU encoder to be summing of the input word vectors. Sentence encoder pretraining also involves discriminative approaches, i.e., classifying input text into a small amount of categories. For example, Kenter et al. (2016) use averaged word embeddings and train their model to classify whether the two input sentence embeddings are from the adjacent sentences. Jernite et al. (2017) train a GRU encoder for predicting discourse-related classification objectives. Logeswaran and Lee (2018) also use a GRU encoder to predict the correct next sentence given a few candidate sentences.
Contextualized Word Representations. Most word representations have one-toone correspondence between words and vectors, neglecting the fact that words have different senses depending on the context in which they are situated. This observation has led to research that extends word representations to a “contextualized” version (Kawakami and Dyer, 2015; Melamud et al., 2016; Peters et al., 2017; Tu et al., 2017a; McCann et al., 2017; Peters et al., 2018), where the outcomes of these methods are deep neural models that encode a word and its surrounding context. Later, the invention of Transformer architecture (Vaswani et al., 2017) led to a series of enormous pretrained models in this direction (Radford et al., 2018; Devlin et al., 2019; Liu et al., 2019; Conneau et al., 2020a), which was the drive behind recent breakthroughs in NLP. The training of these models generally involves recovering the words replaced by a special symbol, e.g., [MASK], in the input (also known as “masked word prediction” or “masked language modeling”) or bidirectional language modeling (i.e., have a separate forward and a backward language models at the same time). Other researchers have proposed alternative training objectives, such as training a discriminator to predict whether each token in a corrupted input was replaced by a sample from a generator model (Clark et al., 2020).
With the contextualized representations, approaches of applying them to downstream tasks have also shifted towards the “pretrain-then-finetune” paradigm from the paradigm where pretrained parameters are often frozen during supervised training for downstream tasks (Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019). The new paradigm initializes the majority parameters of downstream models using pretrained contextualized representations and finetunes the entire neural models using training data for downstream tasks.
Similar to traditional word representations, researchers seek to build sentence representations from contextualized word representations using operations like pooling, e.g., (Reimers and Gurevych, 2019). On the other hand, the fact that contextualized word representations encode sentential context makes sentence and word representations barely distinguishable. For example, BERT (Devlin et al., 2019) has a special symbol [CLS] prepended to input sequences and treats the contextualized word representations of the [CLS] symbol as the sentence representation.
Another relevant research direction looks to convert pretrained language models into a sequence-to-sequence pretrained models for text generations. For example, Ramachandran et al. (2017) and Rothe et al. (2020) initialize the weights of the encoder and decoder in a sequence-to-sequence architecture using pretrained language models and then finetune the whole model on generation tasks.
Pretrained Generation Models. The vector representations for words and sentences described earlier are primarily used for discriminative tasks or as features for various downstream tasks. In contrast, in addition to the discriminative tasks, pretrained generation models look to train models that can generate text. In particular, GPT-2 (Radford et al., 2019) shows that unidirectional language modeling can solve several NLP tasks in a zero-shot and one-shot fashion by unifying different tasks into language modeling using prompts. GPT-3 (Brown et al., 2020) follows GPT-2 but uses larger models and shows impressive one-the-fly few-shot performance (also known as “in-context few-shot learning”) for a diverse set of tasks. XLM (CONNEAU and Lample, 2019) uses masked language modeling for both monolingual and crosslingual data. MASS (Song et al., 2019), BART (Lewis et al., 2020b), and mBART (Liu et al., 2020b) are sequence-to-sequence denoising autoencoders. T5 (Raffel et al., 2020a) and its multilingual counterpart mT5 (Xue et al., 2021) convert any NLP tasks into a text-to-text format. Pegasus (Zhang et al., 2020a) uses gap sentence generation for abstractive summarization. MARGE (Lewis et al., 2020a) uses a sequence-to-sequence framework and learns to reconstruct target text by retrieving a set of related texts.
Benchmarks for Pretrained Models. Pretrained contextualized word representations and generative models, especially the ones built on the transformer architectures, have shown superhuman performance on various NLP benchmarks, such as GLUE (Wang et al., 2018a) and SuperGLUE (Wang et al., 2019), both of which evaluate natural language understanding capabilities. Apart from GLUE and SuperGLUE, there are many other benchmarks that have been proposed to test pretrained models. Particularly, Adi et al. (2017) use synthetic tasks, such as predicting sentence length, to measure the quality of sentence representations. SentEval (Conneau and Kiela, 2018) evaluates quality of sentence representations using several humanannotated datasets. decaNLP (McCann et al., 2018) tries to cover diverse tasks and metrics. Similar to decaNLP, GEM (Gehrmann et al., 2021) is a benchmark focusing on text generation. Dynabench (Kiela et al., 2021) uses human-and-model-in-theloop for dataset creation. KILT (Petroni et al., 2021) evaluates models that condition on specific information in large textual resources. There are also benchmarks measuring the amount of biases in the pretrained models (Nangia et al., 2020; Nadeem et al., 2021).
2.1.2 Formal Preliminaries

Skip-Thought. Skip-thought uses GRU encoders to process the word sequence and uses the encoded representations to generate the previous and next sentences. The framework is inspired by the skip-gram formulation of the Word2Vec model. Formally, the training objective is
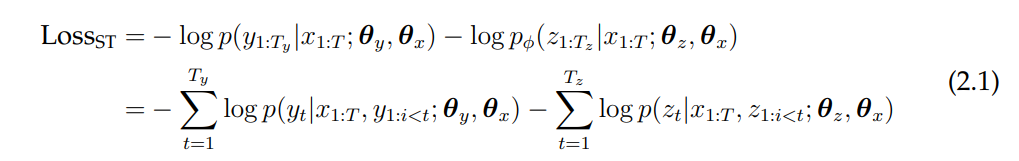
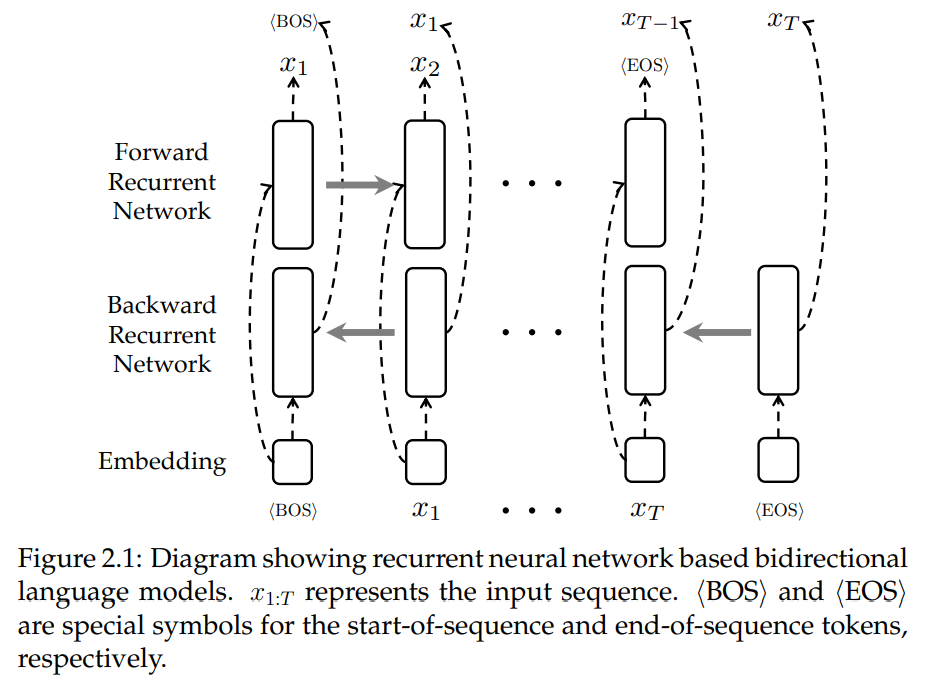

ELMo. ELMo is an LSTM based bidirectional language model (BiLM). While details vary, LSTM-based BiLMs are typically formed by forward and backward language models, which are parameterized by different LSTMs and only share a limited number of parameters. An example of bidirectional language models is shown in Fig. 2.1 where the input word embeddings are shared between two recurrent neural networks. ELMo uses character embeddings. Formally, the training objective of ELMo is
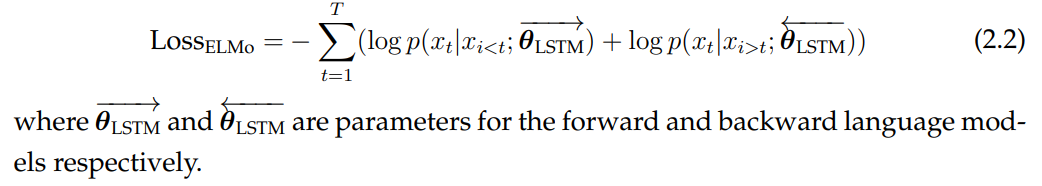

BERT. BERT is a transformer encoder trained with two losses: masked language modeling (MLM) and next sentence prediction (NSP). For NSP, the input sequence is first split into two parts, one of which has a 50% chance of being replaced by a text segment sampled from another document. NSP is a binary classification task that asks models to predict whether the input sequence contains text segments from different documents or not. In practice, BERT uses byte-pair encodings (Sennrich et al., 2016). When formatting input sequences, BERT prepends a special symbol [CLS] to the input and adds a special symbol to the end of the input. When trained with NSP, BERT concatenates the two input segments using a [SEP]. To differentiate the two text segments, BERT also adds segment embeddings to input word embeddings. BERT uses the vector representation of [CLS] to make next sentence predictions with the goal of encouraging models to encode sentential information into the [CLS] representation. Formally, the NSP training objective is
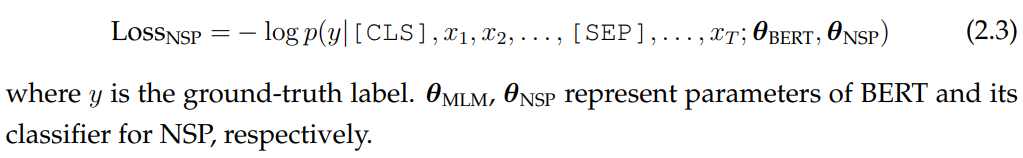
Rather than processing input sequences monotonically like recurrent neural networks, transformer architectures allow BERT to attend to left and right context simultaneously for each position in the input sequence. MLM takes advantage of this feature by a cloze-style formulation that randomly replaces input units with a special [MASK] symbol and asks models to predict the masked units (see Fig. 2.2 for an example). Formally, the MLM training objective is

The final training loss for BERT is
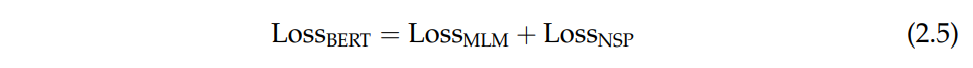
This paper is available on arxiv under CC 4.0 license.
[1] Researchers have also found that using the self-supervised learning objectives on downstream tasks helps model performance on these tasks (e.g., Howard and Ruder, 2018; Gururangan et al., 2020).
[2] While there is work that studies phrases (e.g., two- (Mitchell and Lapata, 2010) and multiple-word (Mikolov et al., 2013b) phrases) and documents (e.g., vector space models in information retrieval (Salton, 1971; Salton et al., 1975)), we focus on sentences as it attracts the most attention in NLP.