Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
4.2.1 Introduction
Pretrained sentence representations have been found useful in various downstream tasks such as visual question answering (Tapaswi et al., 2016), script inference (Pichotta and Mooney, 2016), and information retrieval (Le and Mikolov, 2014; Palangi et al., 2016). However, the focus of pretrained sentence representations has been primarily on a stand-alone sentence rather than the broader context in which it is situated.
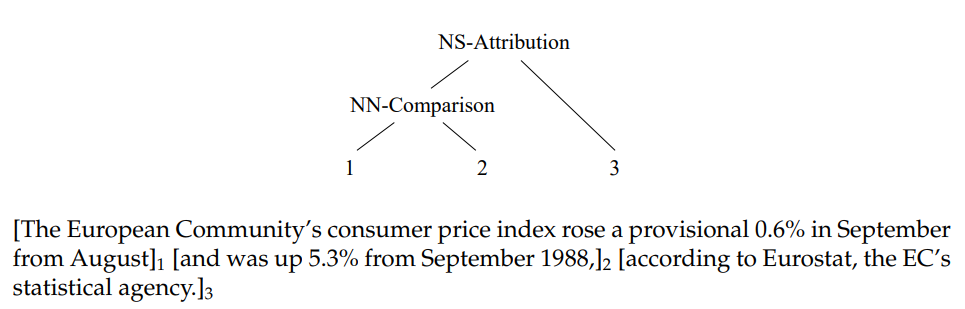
In this work, we seek to incorporate discourse knowledge in general purpose sentence representations. A discourse is a coherent, structured group of sentences that acts as a fundamental type of structure in natural language (Jurafsky and Martin, 2009). A discourse structure is often characterized by the arrangement of semantic elements across multiple sentences, such as entities and pronouns. The simplest such arrangement (i.e., linearly-structured) can be understood as sentence ordering, where the structure is manifested in the timing of introducing entities. Deeper discourse structures use more complex relations among sentences (e.g., tree-structured; see Fig. 4.3).
Theoretically, discourse structures have been approached through Centering Theory (Grosz et al., 1995b) for studying distributions of entities across text and Rhetorical Structure Theory (RST; Mann and Thompson, 1988) for modelling the logical structure of natural language via discourse trees. Researchers have found modelling discourse useful in a range of tasks (Guzman et al. ´ , 2014; Narasimhan and Barzilay, 2015; Liu and Lapata, 2018; Pan et al., 2018), including summarization (Gerani et al., 2014), text classification (Ji and Smith, 2017), and text generation (Bosselut et al., 2018).
We propose a set of novel multi-task learning objectives building upon standard pretrained sentence encoders, which depend only on the natural structure in structured document collections like Wikipedia. Empirically, we benchmark our models and several popular sentence encoders on our proposed benchmark datasets DiscoEval and SentEval (Conneau and Kiela, 2018). Specifically, the DiscoEval has the following tasks:
• As the most direct way to probe discourse knowledge, we consider the task of predicting annotated discourse relations among sentences. We use two humanannotated datasets: the RST Discourse Treebank (RST-DT; Carlson et al., 2001) and the Penn Discourse Treebank (PDTB; Prasad et al., 2008).
• Sentence Position (SP), which can be seen as way to probe the knowledge of linearly-structured discourse, where the ordering corresponds to the timings of events.
• Binary Sentence Ordering (BSO) is a binary classification task to determine the order of two sentences. The fact that BSO only has a pair of sentences as input makes it different from Sentence Position, where there is more context, and we hope that BSO can evaluate the ability of capturing local discourse coherence in the given sentence representations.
• Inspired by prior work on chat disentanglement (Elsner and Charniak, 2008, 2010) and sentence clustering (Wang et al., 2018c), we propose a sentence disentanglement task which seeks to determine whether a sequence of six sentences forms a coherent paragraph. • The Sentence Section Prediction (SSP) task is defined as determining the section of a given sentence. The motivation behind this task is that sentences within certain sections typically exhibit similar patterns because of the way people write coherent text.
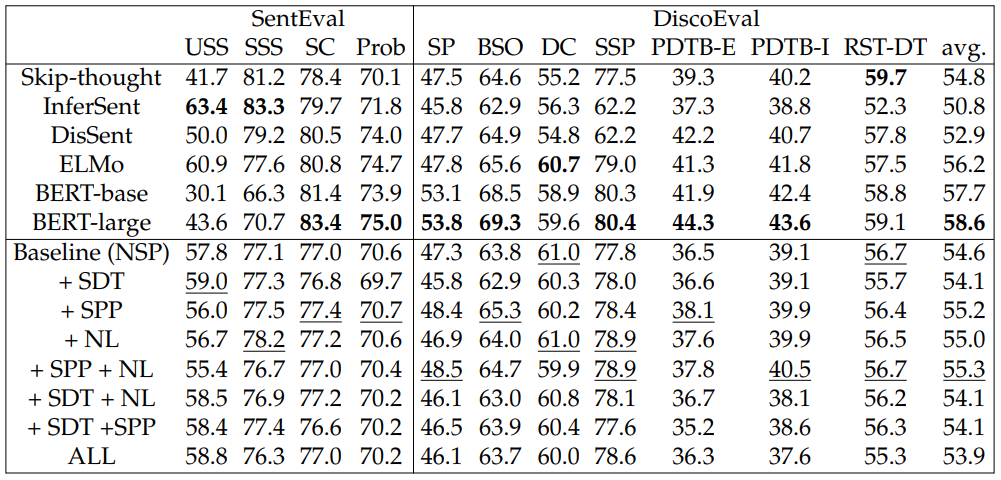
See Chen et al. (2019a) for more details about the benchmark. We find that our proposed training objectives help the models capture different characteristics in the sentence representations. Additionally, we find that ELMo shows strong performance on SentEval, whereas BERT performs the best among the pretrained embeddings on DiscoEval. Both BERT and Skip-thought vectors, which have training losses explicitly related to surrounding sentences, perform much stronger compared to their respective prior work, demonstrating the effectiveness of incorporating losses that make use of broader context.
4.2.2 Related Work
Discourse modelling and discourse parsing have a rich history (Marcu, 2000; Barzilay and Lapata, 2008; Zhou et al., 2010; Kalchbrenner and Blunsom, 2013; Ji and Eisenstein, 2015; Li and Jurafsky, 2017; Wang et al., 2018d; Liu et al., 2018; Lin et al., 2019, inter alia), much of it based on recovering linguistic annotations of discourse structure.
There is work on incorporating discourse related objectives into the training of sentence representations. Jernite et al. (2017) propose binary sentence ordering, conjunction prediction (requiring manually-defined conjunction groups), and next sentence prediction. Similarly, Sileo et al. (2019) and Nie et al. (2019) create training datasets automatically based on discourse relations provided in the Penn Discourse Treebank (PDTB; Lin et al., 2009).
Our work differs from prior work in that we propose novel training signals based on document structure, including sentence position and section titles, without requiring additional human annotation.
4.2.3 Method
All models in our experiments are composed of a single encoder and multiple decoders. The encoder, parameterized by a bidirectional GRU, encodes the sentence, either in training or in evaluation of the downstream tasks, to a fixed-length vector representation (i.e., the average of the hidden states across positions).
The decoders take the aforementioned encoded sentence representation, and predict the targets we define in the sections below. We first introduce Neighboring Sentence Prediction, the loss for our baseline model. We then propose additional training losses to encourage our sentence embeddings to capture other context information.
Neighboring Sentence Prediction (NSP). Similar to prior work on sentence embeddings (Kiros et al., 2015; Hill et al., 2016), we use an encoded sentence representation to predict its surrounding sentences. In particular, we predict the immediately preceding and succeeding sentences. All of our sentence embedding models use this loss. Formally, the loss is defined as

Nesting Level (NL). A table of contents serves as a high-level description of an article, outlining its organizational structure. Wikipedia articles, for example, contain rich tables of contents with many levels of hierarchical structure. The “nesting level” of a sentence (i.e., how many levels deep it resides) provides information about its role in the overall discourse. To encode this information into our sentence representations, we introduce a discriminative loss to predict a sentence’s nesting level in the table of contents:

Sentence and Paragraph Position (SPP). Similar to nesting level, we add a loss based on using the sentence representation to predict its position in the paragraph and in the article. The position of the sentence can be a strong indication of the relations between the topics of the current sentence and the topics in the entire article. For example, the first several sentences often cover the general topics to be discussed more thoroughly in the following sentences. To encourage our sentence embeddings to capture such information, we define a position prediction loss
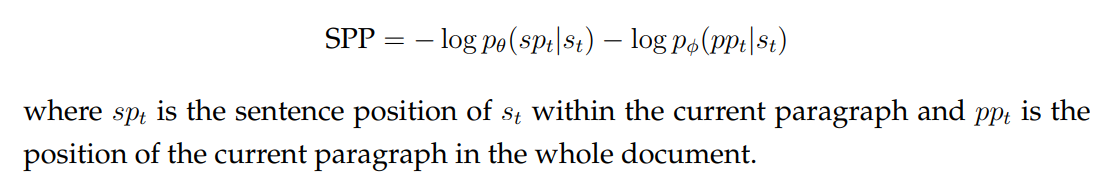
Section and Document Title (SDT). Unlike the previous position-based losses, this loss makes use of section and document titles, which gives the model more direct
access to the topical information at different positions in the document. The loss is defined as

4.2.4 Experiments
Setup. We train our models on Wikipedia as it is a knowledge rich textual resource and has consistent structures over all documents. Details on hyperparameters are in the supplementary material. When evaluating on DiscoEval, we encode sentences with pretrained sentence encoders. Following SentEval, we freeze the sentence encoders and only learn the parameters of the downstream classifier. The “Baseline” row in Table 4.4 are embeddings trained with only the NSP loss. The subsequent rows are trained with extra losses defined in Section 4.2.3 in addition to the NSP loss. Code and data are available at https://github.com/ZeweiChu/DiscoEval.
Additionally, we benchmark several popular pretrained sentence encoders on DiscoEval, including Skip-thought,[3] InferSent (Conneau et al., 2017),[4] DisSent (Nie et al., 2019),[5] ELMo,[6] and BERT.[7] For ELMo, we use the averaged vector of all three layers and time steps as the sentence representations. For BERT, we use the averaged vector at the position of the [CLS] token across all layers. We also evaluate per-layer performance for both models in Section 4.2.5.
When reporting results for SentEval, we compute the averaged Pearson correlations for Semantic Textual Similarity tasks from 2012 to 2016 (Agirre et al., 2012, 2013, 2014, 2015, 2016). We refer to the average as unsupervised semantic similarity (USS) since those tasks do not require training data. We compute the averaged results for the STS Benchmark (Cer et al., 2017), textual entailment, and semantic relatedness (Marelli et al., 2014) and refer to the average as supervised semantic similarity (SSS). We compute the average accuracy for movie review (Pang and Lee, 2005); customer review (Hu and Liu, 2004); opinion polarity (Wiebe et al., 2005); subjectivity classification (Pang and Lee, 2004); Stanford sentiment treebank (Socher et al., 2013); question classification (Li and Roth, 2002); and paraphrase detection (Dolan et al., 2004), and refer to it as sentence classification (SC). For the rest of the linguistic probing tasks (Conneau et al., 2018a), we report the average accuracy and report it as “Prob”.
Results. Table 4.4 shows the experiment results over all SentEval and DiscoEval tasks. Different models and training signals have complex effects when performing various downstream tasks. We summarize our findings below:
• On DiscoEval, Skip-thought performs best on RST-DT. DisSent performs strongly for PDTB tasks but it requires discourse markers from PDTB for generating training data. BERT has the highest average by a large margin, but ELMo has competitive performance on multiple tasks.
• The NL or SPP loss alone has complex effects across tasks in DiscoEval, but when they are combined, the model achieves the best performance, outperforming our baseline by 0.7% on average. In particular, it yields 40.5% accuracy on PDTB-I, outperforming Skip-thought by 0.3%. This is presumably caused by the differing, yet complementary, effects of these two losses (NL and SPP).
• The SDT loss generally hurts performance on DiscoEval, especially on the position-related tasks (SP, BSO). This can be explained by the notion that consecutive sentences in the same section are encouraged to have the same sentence representations when using the SDT loss. However, the SP and BSO tasks involve differentiating neighboring sentences in terms of their position and ordering information.
• On SentEval, SDT is most helpful for the USS tasks, presumably because it provides the most direct information about the topic of each sentence, which is a component of semantic similarity. SDT helps slightly on the SSS tasks. NL gives the biggest improvement in SSS.
• In comparing BERT to ELMo and Skip-thought to InferSent on DiscoEval, we can see the benefit of adding information about neighboring sentences. Our proposed training objectives show complementary improvements over NSP, which suggests that they can potentially benefit these pretrained representations.
4.2.5 Analysis
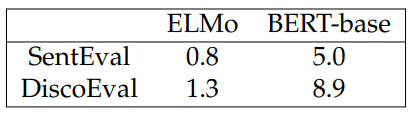
Per-Layer analysis. To investigate the performance of individual hidden layers, we evaluate ELMo and BERT on both SentEval and DiscoEval using each hidden layer. For ELMo, we use the averaged vector from the targeted layer. For BERT-base, we use the vector from the position of the [CLS] token. Fig. 4.4 shows the heatmap of performance for individual hidden layers. We note that for better visualization, colors in each column are standardized. On SentEval, BERT-base performs better with shallow layers on USS, SSS, and Probing (though not on SC), but on DiscoEval, the results using BERT-base gradually increase with deeper layers. To evaluate this phenomenon quantitatively, we compute the average of the layer number for the

best layers for both ELMo and BERT-base and show it in Table 4.5. From the table, we can see that DiscoEval requires deeper layers to achieve better performance. We assume this is because deeper layers can capture higher-level structure, which aligns with the information needed to solve the discourse tasks.
DiscoEval architectures. In all DiscoEval tasks except DC, we use no hidden layer in the neural architectures, following the example of SentEval. However, some tasks are unsolvable with this simple architecture. In particular, the DC tasks have low accuracies with all models unless a hidden layer is used. As shown in Table 4.6,

when adding a hidden layer of 2000 to this task, the performance on DC improves dramatically. This shows that DC requires more complex comparison and inference among input sentences. Our human evaluation below on DC also shows that human accuracies exceed those of the classifier based on sentence embeddings by a large margin.
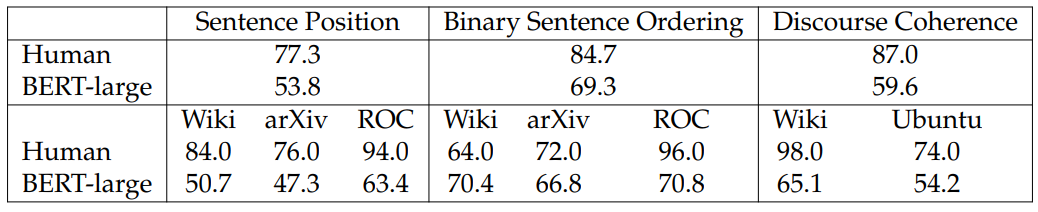
Human Evaluation. We conduct a human evaluation on the Sentence Position, Binary Sentence Ordering, and Discourse Coherence datasets. A native English speaker was provided with 50 examples per domain for these tasks. While the results in Table 4.7 show that the overall human accuracies exceed those of the classifier based on BERT-large by a large margin, we observe that within some specific domains, for example Wiki in BSO, BERT-large demonstrates very strong performance.
Does context matter in Sentence Position? In the SP task, the inputs are the target sentence together with 4 surrounding sentences. We study the effect of removing the surrounding 4 sentences, i.e., only using the target sentence to predict its position from the start of the paragraph.
Table 4.8 shows the comparison of the baseline model performance on Sentence Position with or without the surrounding sentences and a random baseline. Since our baseline model is already trained with NSP, it is expected to see improvements over a random baseline. The further improvement from using surrounding sentences demonstrates that the context information is helpful in determining the sentence position.
This paper is available on arxiv under CC 4.0 license.
[3] github.com/ryankiros/skip-thoughts
[4] github.com/facebookresearch/InferSent
[5] github.com/windweller/DisExtract
[6] github.com/allenai/allennlp
[7] github.com/huggingface/pytorch-pretrained-BERT