
Hello readers, I'm excited to have you join me as we dive into the fascinating world of Large Language Models (LLMs). The development of LLMs has captured the interest of people across various fields. If you're new to this topic, you're in the right place. In this blog, we'll explore transformers, their components, how they work, and much more.
Ready to get started? Let's dive in!
Transformers in NLP
Transformer models are a type of deep learning neural network model that are widely used in Natural Language Processing (NLP) tasks. Transformer models are experts in learning the context of the given input data as a sequence and generating new data out of it. In recent years, transformers have been used as baseline models in many Large Language Models (LLMs).
History of Transformers
The transformer architecture was introduced in June 2017 in the paper "Attention Is All You Need." After the introduction of the transformers, the field of NLP has evolved drastically around the transformers architecture. Many Large Language Models (LLMs) and pre-trained models were launched with a transformer as their backbone. Let's see a brief overview of the evolution of transformers in the field of NLP.
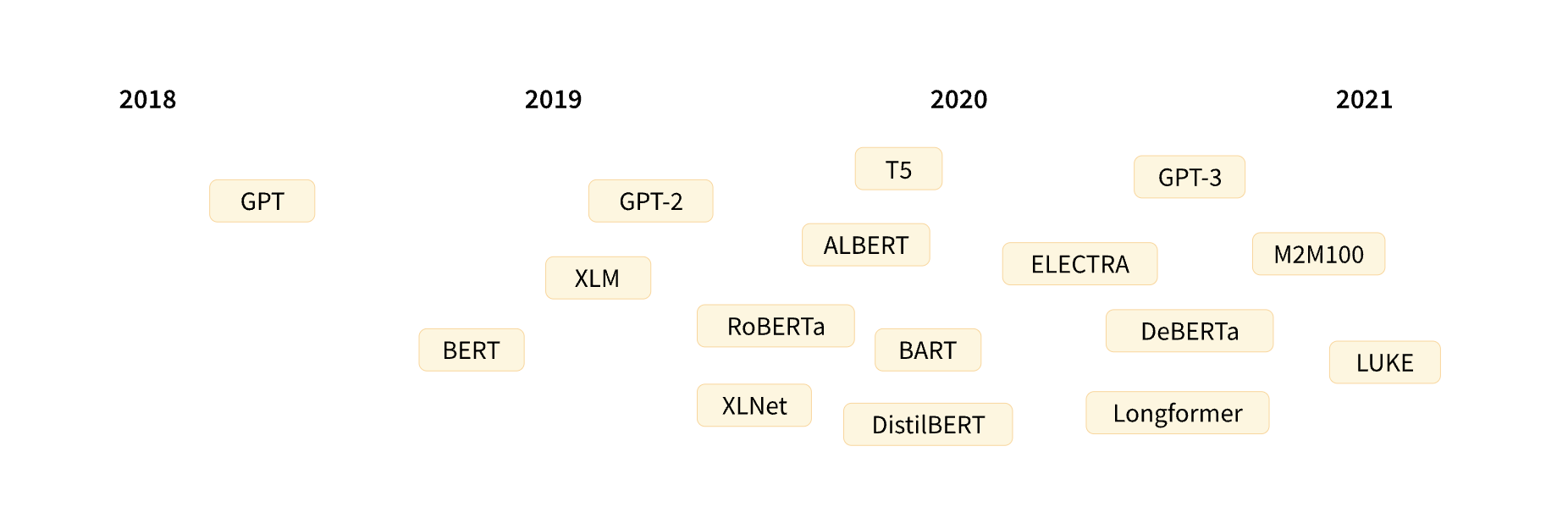
In June 2018, the first transformer-based GPT (Generative Pre-trained Transformers) was introduced. Later in the same year, BERT (Bi-directional Encoder Representations from Transformers) was launched. In February 2019, the advanced version of GPT, i.e., GPT-2, was launched by OpenAI. In the same year, many pre-trained models, such as XLM and RoBERTa, were put in place, making the field of NLP even more competitive.
From the year 2020, the field of NLP boomed with many new pre-trained models being launched. The growth of these models was largely dependent on the transformer architecture. The above are only a few representatives from the list, whereas, in real-world scenarios, there are even many models developed on the transformer architecture.
Before we explore the structure of transformers, let's first understand some basic concepts.
Pre-Training
Pre-training is an act of training a Machine Learning (ML) model from scratch. The training procedure starts by initially randomizing the weights of the model. During this phase, a massive corpus of data is fed to the model for learning. Typically, this training phase is costly and time-consuming.
Fine-Tuning
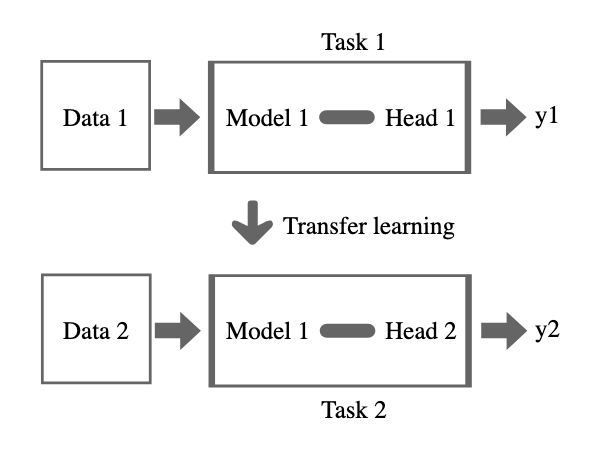
Fine-tuning is a training procedure carried out on a pre-trained model with domain-specific information. Pre-trained models have gained extensive knowledge, making them less suitable for specific domains. During this process, the pre-trained model is re-trained, but with a reduced cost since it has already learned some concepts.
To perform fine-tuning on a pre-trained model, we employ the technique of transfer learning. Transfer learning is a machine learning method where a model applies its knowledge learned from one use case to predict inferences in another use case.
Encoder
An encoder in a transformer takes the sequence of data as input and generates a sequence of vectors for the given input sequence. Encoder models accomplish this by utilizing the self-attention layers present in them. We will discuss these self-attention layers in more detail later.
These models are frequently described as having "bidirectional" attention and are often referred to as auto-encoding models. Encoder models are primarily employed in Sentence classification and Named Entity Recognition (NER).
Encoder-only models are transformer models that only have encoders in their architecture. They are very efficient in use cases like text classification, where the model aims to understand the underlying representation of the text.

Decoder
A decoder in a transformer takes a sequence of vectors as input and produces a sequence of output tokens. These output tokens are the words in the generated text. Like encoders, decoders also use many self-attention layers. The pre-training of decoder models usually revolves around predicting the next word in the sentence. These models are best suited for tasks involving text generation.
Decoder-only models are transformer models that only have decoders in their architecture. They are very efficient at text generation. Decoders are specialized in generating output tokens (text). Machine translation and text summarization are a few use cases where the decoder-only models excel.
Attention Layers
The self-attention layers in the transformer allow the model to learn the long-range dependencies between the words in the input text.
In other words, this layer will instruct the model to pay more attention to specific words in the given input text.
The model does this by calculating the similarity score between pairs of text in the input sequence. The layer then uses this score to calculate the weights of the input vector. The output of these layers is the weighted input vectors.
Now that you have an idea about the basic concepts of encoders, decoders, and attention layers, let's dive into the architecture of transformers.
Architecture of Transformers
The structure of a transformer model resembles the image shown below.
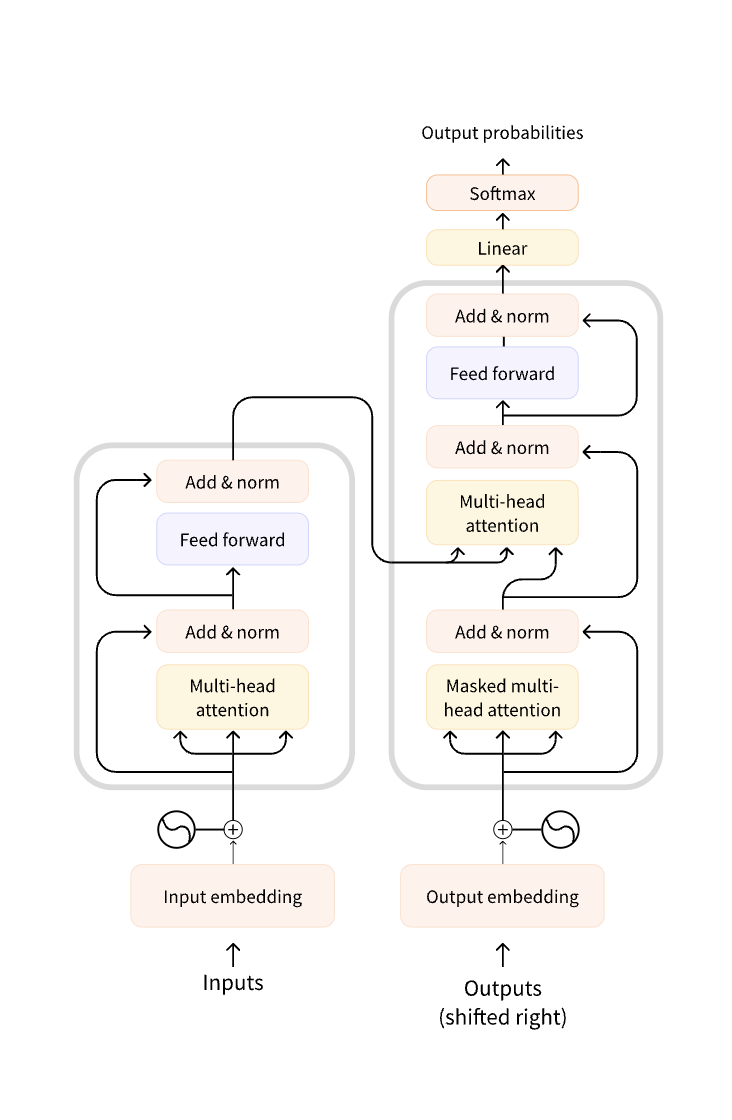
The encoders are placed on the left side, and the decoders are placed on the right side. The encoders accept the sequence of text as input and produce a sequence of vectors as output, which are fed as input to the decoders. The decoders will generate a sequence of output tokens. The encoders are stacked with self-attention layers.
Each layer takes an input vector and returns a weighted input vector based on the self-attention mechanism, which we discussed already. The weighted sum is the output of the self-attention layer.
The decoder also contains a stack of self-attention layers and a Recurrent Neural Network (RNN). The self-attention layers work the same way as the encoders, but the RNN will take responsibility for converting the weighted sum of vectors to output tokens. Hence, it should be clear by now that the RNN accepts the weighted vectors as input and generates the output tokens as output. In simple words, output tokens are the words present in the output sentence.
To get a code-level understanding of transformers, I would appreciate you having a look into this PyTorch implementation of Transformers.
Conclusion
Transformers have revolutionized the field of Artificial Intelligence (AI) and Natural Language Processing (NLP) by excelling at handling large amounts of data. Leading models like Google's BERT and OpenAI's GPT series showcase their transformative effect on search engines and text generation.
Consequently, they have become essential in modern machine learning, pushing the limits of AI and creating new opportunities for technological progress. As a result, they have become indispensable in modern machine learning, driving forward the boundaries of AI and opening new avenues in technological advancements.
Happy learning!
References
Refer to the other articles of this series on Large Language Models (LLMs):
https://hackernoon.com/large-language-models-a-beginners-journeypart-1?embedable=true