
Hello readers, I'm excited to have you join me as we dive into the fascinating world of Large Language Models (LLMs). The development of LLMs has captured the interest of people across various fields. If you're new to this topic, you're in the right place. In this blog, we'll explore what Large Language Models are, the components of an LLM, how they learn, their limitations, and much more.
Ready to get started? Let's dive in!
What are Large Language Models?
A Large Language Model (LLM) is a type of Artificial Intelligence (AI) designed to recognize and generate text. These models are trained on vast datasets, enabling them to understand complex relationships and patterns in the input data and generate coherent responses.
Breakdown of LLM:
-
Large: The term "Large" signifies the massive scale of these models. This includes the vast amount of data they are trained on and the huge number of internal neurons in their architecture. The larger the model, the more data it can process and learn from, enhancing its performance and accuracy.
-
Language Model: A language model is designed to predict the next word in a sentence. For instance, in the sentence "I like to ___," the model might predict the next word as "sports," "music," or "movies." This predictive capability is fundamental to how language models generate coherent and contextually relevant text.
LLMs leverage Deep Learning (DL), a subset of Machine Learning (ML), to accomplish this. Specifically, they use a type of Neural Network known as Transformers. No worries if you’re not familiar with transformers yet. We’ll explore them in detail shortly.
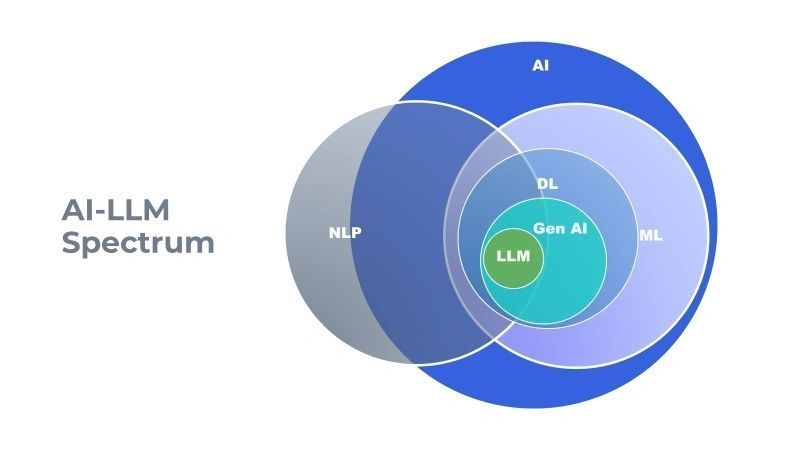
Let me provide a clearer breakdown of the layers in the field of AI:
-
Artificial Intelligence (AI): This term encompasses techniques and technologies for imbuing machines with intelligence.
-
Machine Learning (ML): ML is a subset of AI focused on recognizing patterns within data. Models are trained on datasets to understand and apply these patterns to new, unseen data. Techniques such as supervised, unsupervised, and semi-supervised learning fall within this category.
-
Deep Learning (DL): DL is a specialized area within ML that deals with unstructured data, such as images, videos, and gifs. Neural networks are used to analyze complex relationships on a large scale. These networks, inspired by the human brain's neural system, contain neurons that process information. Transformers, a well-known example of neural networks, will be discussed in more detail later.
-
Large Language Model (LLM): LLMs utilize transformers to comprehend and generate text. We'll delve into their architecture and functionality in the upcoming topics.
Now that we have a good grasp of what LLMs are and their place in the AI spectrum, let's delve deeper into their components.
Components of a Large Language Model
The three main components of a Large Language Model (LLM) are data, architecture, and training. Let's briefly discuss each one:
-
Data: The data used to train an LLM is critical for its performance. The richer and more contextual the data, the better the model learns. LLMs are trained on a diverse range of open-source data, including Wikipedia articles, public forums, books, articles, websites, and other written documents. This extensive dataset helps the model acquire a broad knowledge base.
-
Architecture: The architecture of an LLM refers to its foundational design, which is typically based on the Transformer model. Transformers use neural networks that excel at handling sequential text data. They incorporate mechanisms like encoders, decoders, feed-forward layers, and attention mechanisms, which help the model prioritise the most relevant parts of the input data. Here's a detailed look at the Transformer architecture. We will discuss in detail about the transformer architecture in the upcoming blogs.
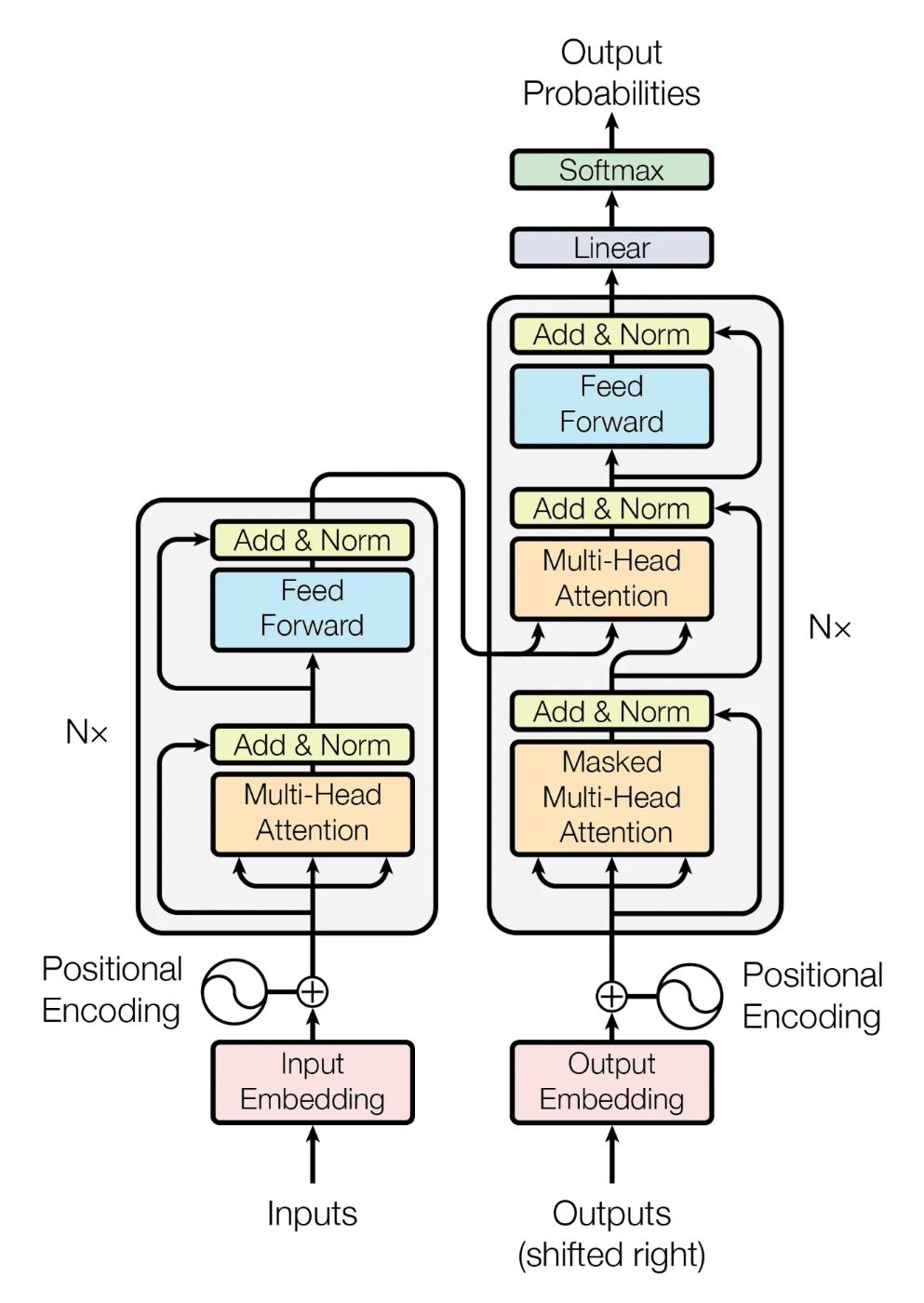
-
Training: Training is the process where the LLM is exposed to the pre-collected dataset. During this phase, the model adjusts its internal parameters to reduce errors and improve learning. The training process focuses on understanding the underlying data patterns, grammar, and factual content. We'll dive deeper into the training phase next.
Training a Large Language Model
The effectiveness of an LLM largely hinges on its training, which comprises two primary phases, with a third phase being optional.
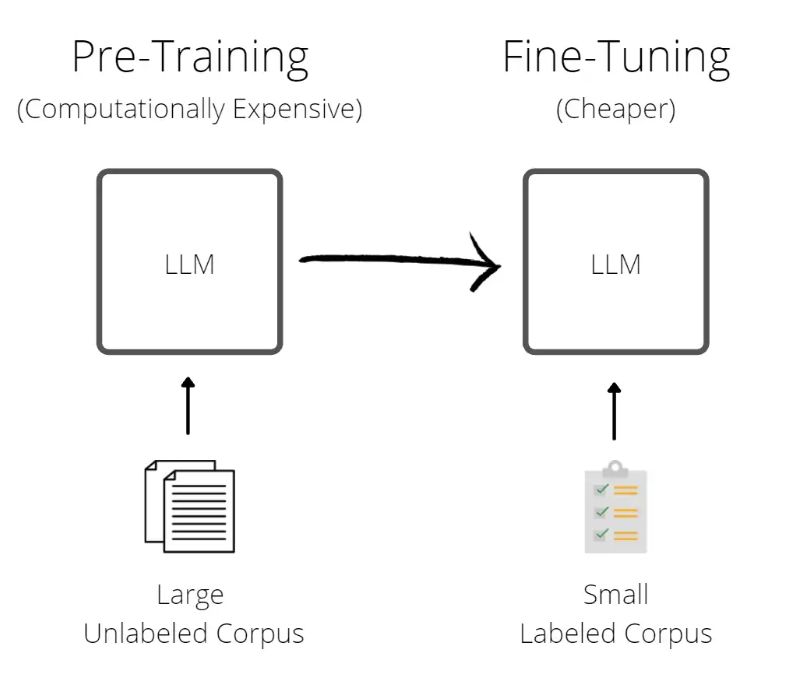
Let's delve into each phase:
-
Pre-training: During this initial phase, the LLM is immersed in a vast array of data sourced from open-access domains. This corpus typically includes Wikipedia articles, books, public documents, and more. The objective is to expose the model to a wide spectrum of linguistic patterns and semantic connections inherent in the language. By processing billions of data samples, the LLM gradually acquires an understanding of grammar, facts, and contextual nuances present within the data.
-
Instruction Fine-tuning: Following pre-training, the LLM enters the fine-tuning phase, where it is tailored to specific instructional contexts. In this supervised learning approach, the pre-trained model is further refined using domain-specific data and corresponding instructions. Users provide input instructions along with the desired output, enabling the LLM to grasp and execute specific tasks or generate content pertinent to those instructions.
-
Reinforcement Learning from Human Feedback (Optional): While optional, many LLMs, such as ChatGPT and Gemini, undergo an additional phase of reinforcement learning. During this phase, the model collects feedback from human users regarding the quality of its generated responses. Positive feedback serves as reinforcement, encouraging the model to retain successful strategies, while negative feedback prompts adjustments and refinements. This iterative process enables the LLM to continually improve its performance based on human interaction, refining its output over time.
By undergoing these training phases, LLMs evolve from generic language models into specialized, task-oriented systems capable of comprehending user instructions and generating contextually relevant content.
Use Cases of Large Language Models
LLMs have a broad range of applications across various industries. Let's explore a few key areas where they are particularly impactful:
-
Content Generation: LLMs are extensively utilized in content creation and content marketing due to their ability to produce human-like text. They can generate high-quality blogs and articles with rich contextual information. (P.S. This article is not generated by an LLM 😅).
-
Sentiment Analysis: LLMs are adept at extracting sentiment from text. Their capability to understand the underlying patterns in input data allows them to determine the sentiment and mood of the content. This is especially useful in customer support, where understanding customer sentiment is crucial.
-
Code Generation: Beyond generating open-domain text, some LLMs are trained on open-source codebases. This enables them to generate code for software development and testing in various programming languages, making them valuable tools for developers.
-
Text Summarisation: LLMs can comprehend lengthy documents and articles, extracting key information through attention-based mechanisms. This ability to summarise content is invaluable in sectors where large volumes of data need to be processed, making it easier to digest and act upon critical information.
These examples highlight just a few of the general use cases where LLMs excel in everyday activities.
Limitations of Large Language Model
While Large Language Models (LLMs) demonstrate remarkable abilities in understanding and creating language, they face certain constraints that can hinder their effectiveness in real-world scenarios.

These limitations include:
-
Contextual Understanding: LLMs may struggle to grasp the full context of a given task, resulting in inaccurate or irrelevant output. Without a deep understanding of the surrounding context, the generated content may miss the mark in conveying the intended message.
-
Generic Responses: LLMs might generate responses that are too generic and fail to address the specific needs or nuances of the user or situation. This can lead to impersonal or inadequate outputs that do not fulfill the intended purpose.
-
Vocabulary Limitations: LLMs trained on general datasets may lack the specialized vocabulary required for certain specialized fields or tasks. Consequently, they may find it challenging to accurately convey technical or complex information, limiting their utility in those areas.
-
Hallucination: There are instances where LLMs fabricate information or produce outputs that are biased, inaccurate, or misleading. This phenomenon, known as hallucination, occurs when the model extrapolates beyond the scope of the provided data, resulting in unreliable or erroneous results.
These LLM limitations offer opportunities for improvement through various strategies. These include Retrieval Augmented Generation (RAG), Prompt Engineering, and fine-tuning LLMs on domain-specific datasets. These strategies enable us to overcome challenges such as missing context, non-tailored outputs, limited specialized vocabulary, and hallucination. I'll delve deeper into addressing these limitations in a separate part of this series.
Conclusion
In summary, Large Language Models (LLMs) have great potential to change how we interact with technology. We've learned about what they are, how they work, and where they're used. While they can do amazing things, like writing articles and understanding sentiment, they also have limits, like sometimes not understanding context well. But, we're finding ways to make them better. As we continue exploring LLMs, let's remember to use them responsibly and make the most out of their capabilities for the benefit of everyone. Keep an eye out for more discussions on this exciting topic!
Wishing you an enjoyable and fruitful learning journey!
Learning Resources
Here are some other resources that you may find helpful: