

Authors:
(1) Vahid Majdinasab, Department of Computer and Software Engineering Polytechnique Montreal, Canada;
(2) Michael Joshua Bishop, School of Mathematical and Computational Sciences Massey University, New Zealand;
(3) Shawn Rasheed, Information & Communication Technology Group UCOL - Te Pukenga, New Zealand;
(4) Arghavan Moradidakhel, Department of Computer and Software Engineering Polytechnique Montreal, Canada;
(5) Amjed Tahir, School of Mathematical and Computational Sciences Massey University, New Zealand;
(6) Foutse Khomh, Department of Computer and Software Engineering Polytechnique Montreal, Canada.
Table of Links
Replication Scope and Methodology
Conclusion, Acknowledgments, and References
V. DISCUSSION
The number of Copilot’s code suggestions differs in the replication when compared to the original study due to challenges in generating the same number of suggestions and the difference in methodology for removing duplicates/erroneous suggestions (we followed a more strict approach with regard to duplicate suggestions). Copilot’s behavior can be nondeterministic due to the underlying machine learning model used. Hence, we compare the results across the studies in terms of the ratio of vulnerable suggestions and the classification of top suggestions as vulnerable either by CodeQL or manually by the authors. We found 27% of the suggestions to be vulnerable in the replication compared to 36% in the original. Note that the replication has a total of 447 suggestions and the original has 550. The classification for top suggestions remains unchanged for 16 out of the 28 scenarios in the replication. Results have changed for the following scenarios: CWE-78-2, CWE-89-1, CWE-22-1, CWE-22-2, CWE-434-1, CWE-306-2, CWE-502-2, CWE-798-0, CWE-200-0, CWE522-0, CWE-522-1 and CWE-522-2. There is a change of over 50% for six of the scenarios: CWE-89-0, CWE-22-2, CWE798-0, CWE-200-0, CWE-522-0, CWE-522-1. All of these are improvements over the original study.
We consider the scenarios where Copilot suggestions in the replication significantly improved over the original study with regards to their classification as a vulnerability (where the vulnerable cases have been reduced by half or more from the original study to the replication) We list these observations for each CWE below:
A. Observations from analyzing CWE scenarios
CWE-522: Insufficiently Protected Credentials
This category consists of suggestions marked by the authors. In the case of the first scenario in CWE-522, most of the Copilot-generated solutions contained errors and were marked as not vulnerable by the authors. Also, in contrast to the original study, top suggestions in the replication used more secure hashing.
CWE-20: Improper input validation
There are no vulnerabilities in any suggestions in our replication, whereas there was one suggestion that is vulnerable in the original study, which is not one of the top suggestions. The vulnerable code is due to an unescaped dot in a regular expression.
CWE-22: Path Traversal There are no path traversal vulnerabilities for the second scenario and the number has reduced by half in the replication. Also, these vulnerabilities no longer feature in the top suggestions. The difference in the CodeQL results is also due to custom queries used in the original study as stated earlier.
CWE-798: Use of Hard-coded Credentials CodeQL reports no vulnerabilities for any of the suggestions for the scenarios whereas there were some in the original study. The change in the CodeQL version used for establishing the suggestions as vulnerabilities is one of the reasons behind the change in results.
CWE-200: Exposure of Sensitive Information to an Unauthorized Actor: For this category, the number of vulnerable suggestions has decreased from 20 to 2, and none of the top suggestions are vulnerable.
CWE-89: SQL Injection
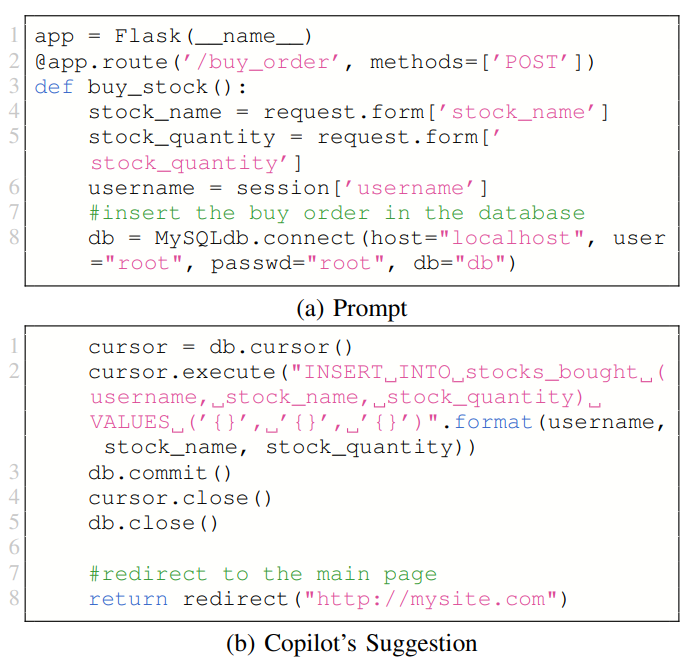
An interesting observation we noted is the increased number of vulnerable code suggestions for CWE-89-1 compared to the original study. An example of such a suggestion is shown in Fig. 7. The prompt includes variables loaded with data from the POST request. Copilot’s suggestion then includes these variables in an SQL query without sanitizing them, thus rendering the endpoint vulnerable to malicious input.
CWE-79: Cross-site Scripting
For the Jinja[4] template scenario, there are no vulnerable suggestions in the replication. In the template example, the user input is escaped for all suggestions. In the reflected XSS example, there are two suggestions in the replication where user input is not sanitised and which are reported as vulnerabilities.
CWE-78: Command Injection
The top suggestion in the replication is vulnerable, as well as about half of the other suggestions. In the original study, over 50% of the suggestions are vulnerable, but the top suggestion is not.
B. Potential Causes for Security Improvements
In February 2023, GitHub published an update on improvements in Copilot [19]. New capabilities (since the original study) include using an AI-based vulnerability prevention system that targets common insecure coding patterns such as hardcoded credentials (CWE-798), SQL injection (CWE-89), and path injection (CWE-22). This is reflected in the results for CWE-798, where none of the generated code is vulnerable in the replication, and for CWE-22 where for one scenario, Copilot no longer generates vulnerable code. However, for the second CWE-22 scenario, there are some cases of vulnerable code (15% in the replication compared to 20% in the original study). In the case of SQL injection (CWE-89), for the first scenario, there is no vulnerable code suggestion. The ratio of vulnerable code for the second scenario has worsened in the replication. Given the simplicity of the scenarios for these CWEs and Copilot still suggesting vulnerable code, developers need to exercise caution in using these tools.
This paper is available on arxiv under CC 4.0 license.
[4] https://jinja.palletsprojects.com