Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
3.1.1 Introduction
Pretraining of large transformers has led to a series of breakthroughs in language representation learning (Radford et al., 2018; Devlin et al., 2019). Many nontrivial NLP tasks, including those that have limited training data, have greatly benefited from these pretrained models. Given the importance of model sizes, we ask: Is having better NLP models as easy as having larger models?
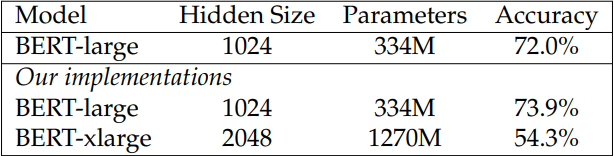
We observe that simply growing the hidden size of a model such as BERT-large (Devlin et al., 2019) can lead to worse performance. Table 3.1 shows an example where we increase the hidden size of BERT-large to be 2 times larger but do not obtain better results.
In this paper, we address this problem by designing A Lite BERT (ALBERT) architecture that has significantly fewer parameters than a traditional BERT architecture.
ALBERT incorporates two parameter reduction techniques: embedding matrix factorization (Grave et al., 2017; Baevski and Auli, 2019) and cross-layer parameter sharing (Dehghani et al., 2019). To further improve the performance of ALBERT, we also introduce a self-supervised loss for sentence ordering prediction (SOP). SOP primarily focuses on inter-sentence coherence and is designed to address the ineffectiveness (Yang et al., 2019; Liu et al., 2019) of the NSP loss proposed in the original BERT paper.
As a result of these design choices, we are able to scale up to much larger ALBERT configurations that still have fewer parameters than BERT-large but achieve significantly better performance. We also establish new state-of-the-art results on several popular NLP benchmarks.
3.1.2 Related Work
ALBERT uses a pretraining loss based on predicting the ordering of two consecutive segments of text. Several researchers have experimented with pretraining objectives that similarly relate to discourse coherence. Coherence and cohesion in discourse have been widely studied and many phenomena have been identified that connect neighboring text segments (Hobbs, 1979; Halliday and Hasan, 1976; Grosz et al., 1995a). Most objectives found effective in practice are quite simple. Skip thought (Kiros et al., 2015) and FastSent (Hill et al., 2016) sentence embeddings are learned by using an encoding of a sentence to predict words in neighboring sentences. Other objectives for sentence embedding learning include predicting future sentences rather than only neighbors (Gan et al., 2017) and predicting explicit discourse markers (Jernite et al., 2017; Nie et al., 2019).
Our loss is most similar to the sentence ordering objective of Jernite et al. (2017), where sentence embeddings are learned in order to determine the ordering of two consecutive sentences. Unlike most of the above work, however, our loss is defined on textual segments rather than sentences. BERT uses a loss based on predicting whether the second segment in a pair has been swapped with a segment from another document. We compare to this loss in our experiments and find that sentence ordering is a more challenging pretraining task and more useful for certain downstream tasks.
Concurrently to this work, Wang et al. (2020) also try to predict the order of two consecutive segments of text, but they combine it with the original next sentence prediction in a three-way classification task rather than empirically comparing the two.
3.1.3 Method
The backbone of the ALBERT architecture is similar to BERT in that it uses a transformer encoder (Vaswani et al., 2017) with GELU nonlinearities (Hendrycks and Gimpel, 2016). We follow the BERT notation conventions and denote the vocabulary embedding size as E, the number of encoder layers as L, and the hidden size as H. Following Devlin et al. (2019), we set the feed-forward/filter size to be 4H and the number of attention heads to be H/64
Sentence Ordering Prediction. BERT is trained jointly by MLM and NSP. NSP is a binary classification task for predicting whether two segments appear consecutively in the original text. Positive examples are created by taking consecutive segments from the training corpus. Negative examples are created by pairing segments from different documents. Positive and negative examples are sampled with equal probability. Later studies (Yang et al., 2019; Liu et al., 2019) show that NSP has little impact on improving downstream task performance.
We conjecture that the main reason behind NSP’s ineffectiveness is its lack of difficulty as a task, as compared to MLM. As formulated, NSP conflates topic prediction and coherence prediction. [1] However, topic prediction is easier to learn compared to coherence prediction.
We argue that inter-sentence modeling is an important aspect of language understanding. Therefore we propose a loss based primarily on coherence. That is, for ALBERT, we use a sentence ordering prediction (SOP) loss, which avoids topic prediction and instead focuses on modeling inter-sentence coherence. The SOP constructs positive examples the same as BERT (two consecutive segments from the same document) and negative examples using the same two consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about discourse-level coherence properties.
3.1.4 Experiments

We generate masked inputs for the MLM targets using n-gram masking (Joshi et al., 2020b), with the length of each n-gram mask selected randomly. The probability for the length n is given by
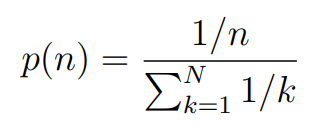
We set the maximum length of n-gram (i.e., n) to be 3 (i.e., the MLM target can consist of up to a 3-gram of complete words, such as “White House correspondents”).
All the model updates use a batch size of 4096 and a LAMB optimizer with learning rate 0.00176 (You et al., 2020). We train all models for 125,000 steps unless otherwise specified. Training was done on Cloud TPU V3. The number of TPUs used for training ranged from 64 to 1024, depending on model sizes. Code and pretrained models are available at https://github.com/google-research/albert.
Evaluation Benchmarks. Following Yang et al. (2019) and Liu et al. (2019), we evaluate our models on three popular benchmarks: GLUE benchmark (Wang et al., 2018a), two versions of the SQuAD Dataset Rajpurkar et al. (2016, 2018), and the RACE dataset (Lai et al., 2017). For completeness, we provide description of these benchmarks in Appendix A.2. As in Liu et al. (2019), we perform early stopping on the development sets, on which we report all comparisons except for our final comparisons based on the task leaderboards, for which we also report test set results. For GLUE datasets, we report medians over five runs.
Comparing SOP to NSP. We compare head-to-head three experimental conditions for the additional inter-sentence loss: none (XLNet- and RoBERTa-style), NSP (BERTstyle), and SOP (ALBERT-style), using an ALBERT-base configuration. Results are shown in Table Table 3.2, both over intrinsic and downstream tasks.

The results on the intrinsic tasks reveal that the NSP loss brings no discriminative power to the SOP task (52.0% accuracy, similar to the random-guess performance for the “None” condition). This allows us to conclude that NSP ends up modeling only topic shift. In contrast, the SOP loss does solve the NSP task relatively well (78.9% accuracy), and the SOP task even better (86.5% accuracy). Even more importantly, the SOP loss appears to consistently improve downstream task performance for multisentence encoding tasks (around +1% for SQuAD1.1, +2% for SQuAD2.0, +1.7% for RACE), for an average score improvement of around +1%.
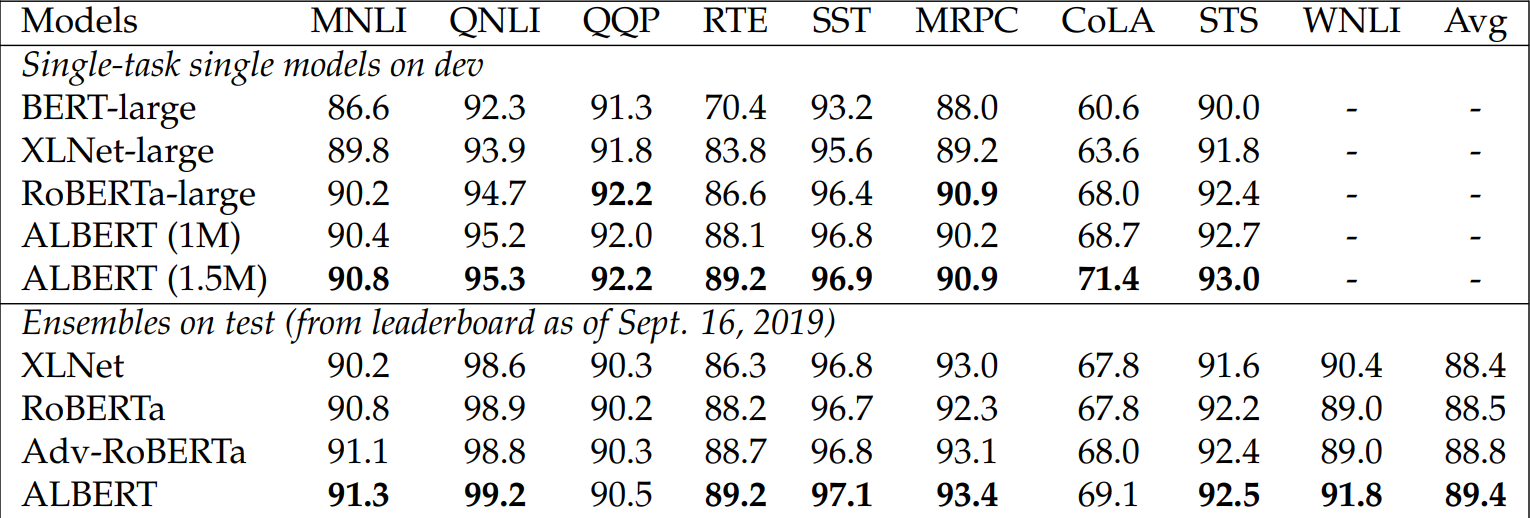
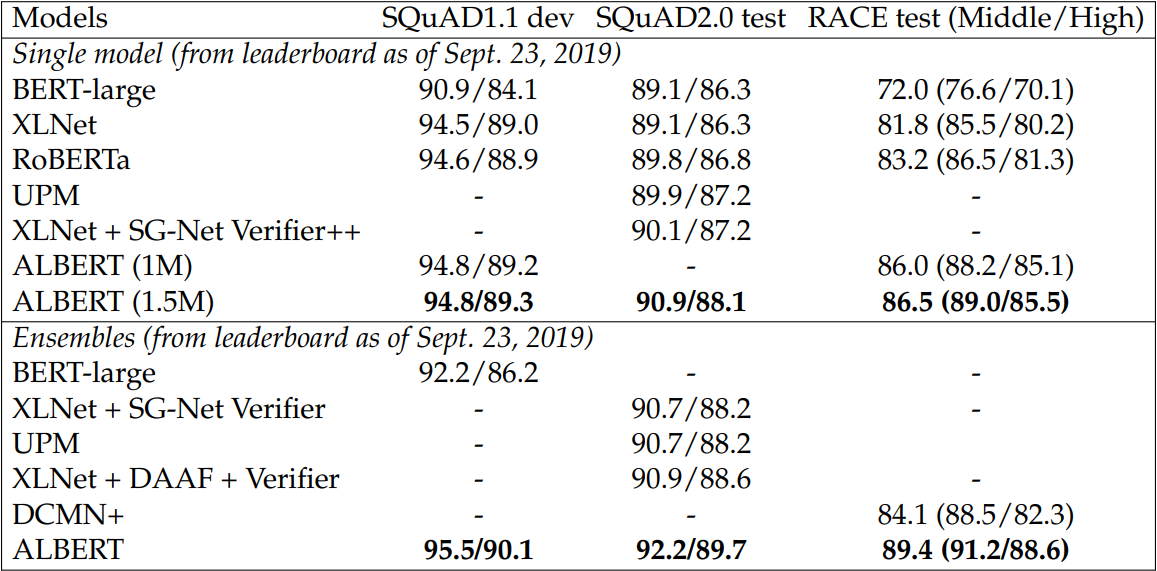
Comparing ALBERT to State-of-the-Art Models. The results we report in Table 3.3 and Table 3.4 use the additional data described in Liu et al. (2019) and Yang et al. (2019). These two tables show that ALBERT achieves state-of-the-art results under two settings: single-model and ensembles.
When ensembling models, for GLUE benchmark and RACE, we average the model predictions for the ensemble models, where the candidates are fine-tuned from different training steps using the 12-layer and 24-layer architectures. For SQuAD, we average the prediction scores for those spans that have multiple probabilities; we also average the scores of the “unanswerable” decision.
Both single-model and ensemble results indicate that ALBERT improves the state-of-the-art significantly for all three benchmarks. For RACE, our single model achieves an accuracy of 86.5%, which is still 2.4% better than the current state-of-theart ensemble model.
This paper is available on arxiv under CC 4.0 license.
[1] Since a negative example is constructed using material from a different document, the negative example segment is misaligned both from a topic and from a coherence perspective.