
The Problem
The analytics service faced a unique problem - it needed to process and store millions of requests per day as cheaply as possible.
Initially, it was hosted on a simple single-node server, which was a good idea at the start of the project, but now, it needed to scale. The question was how to move to a more flexible architecture as smoothly as possible.
Possible Solutions
The first thing I thought was "Just add more power to the machine." It's called "vertical scaling." Adding more resources to the server might help in the short term and might even be cost-effective, but it comes with its own caveats. It might also be a bit easier to develop and manage because it relies on only one server.
But one server, even a powerful one, would be a single point of failure. This means that if it went down for any reason, the whole system would be inaccessible, which is not acceptable for a high-demand service.
The other possible solution would be to split the application into several services, each responsible for its own, dedicated type of task. This could reduce the load on each service, but the problem would be that they would still be relying on vertical scaling alone. It would also be difficult to maintain such an architecture, as everything would now be an individual service, and we would have to set up proper communication between them.
It would also lead to a lot of code repetition, make testing and debugging more difficult (remember that each service is not individual, so they all have their own sets of logs and coverage tests), and generally leave us with complex orchestration later on.
I believe that microservice architecture works well for large enterprises, where there are sometimes teams dedicated to a single service, but it was just not a good fit for us.
The Breakthrough
After considering possible architectures, I decided to try replicating our existing application with a few workers and hosting them on individual servers. The approach is similar to NodeJS built-in clustering, but instead of creating workers within a VM, we create them in new VMs.
This architecture allows us to scale the VMs vertically or add more servers (horizontal scaling) as needed. It also gives us more flexibility as we can stop, scale up, or scale down any machine at any time.
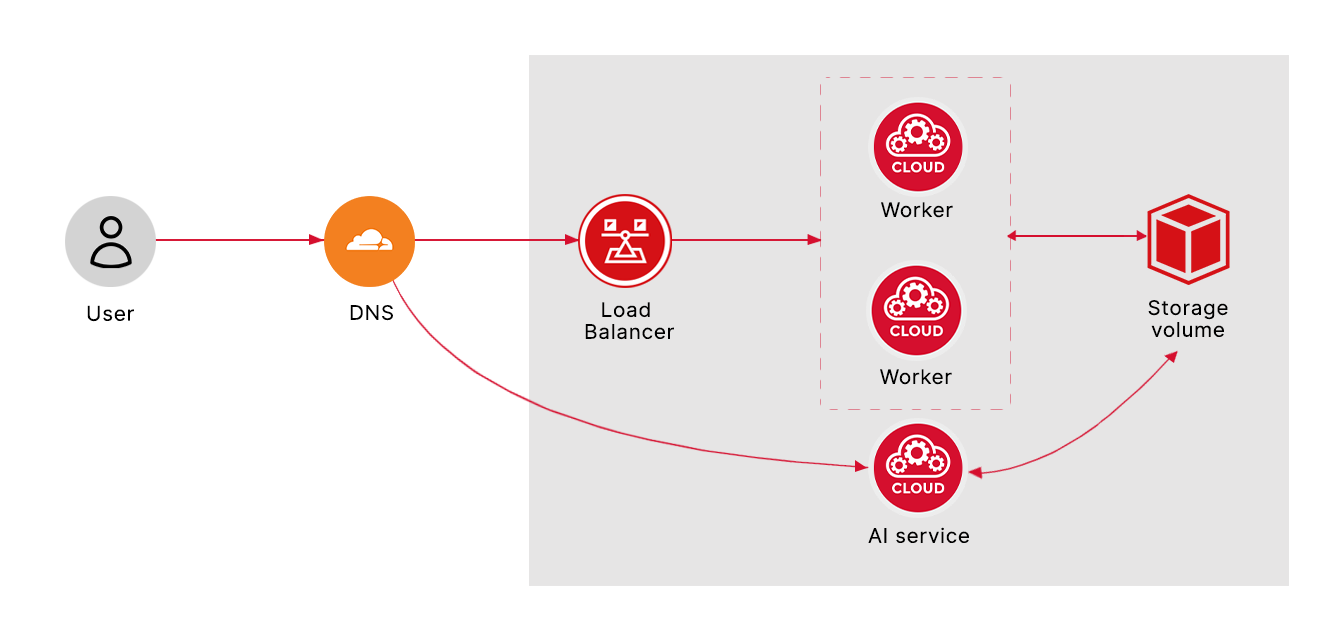
Requests to our server go through a load balancer, which routes the request to the least busy worker. The load balancer is also responsible for managing the HTTPS certificates for the domain itself. If we wanted to do "white label analytics" where each customer could have their own dedicated dashboard, it would be easy to automate this process by assigning certificates with the load balancer and managing the dashboards with Traefik.
The database services and workers are now separate and communicate over a private network. This gives us even more flexibility because the storage service and workers are independent, and it also ensures that no one can access the database from the Internet because of strict firewall rules. We can give the databases more available storage without having to scale the worker services. It also makes backups easier.
Workers are now assigned different roles - a master worker and a regular worker. They behave in much the same way, except that the master worker must perform scheduled tasks (such as moving analytics data from the cache to the database or preparing email reports) to prevent the same task from being performed by workers.
And the services are able to communicate with each other using Redis, which is really helpful for us - when each individual worker receives an analytics request, it can store it in the Redis cache for the master service to process later.
Optimizing Performance and Cost
The new architecture now processes around 10,000 requests per minute. We've seen a 30% reduction in processing time, which demonstrates the new efficiency and scalability of the system. And the best part is the simplicity - it's easy to maintain, and we can always scale it up or down if we need to.
It's also a very affordable solution, with Hetzner charging around £50 per month, whereas a similar setup on GCP would cost us thousands of pounds.