
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Jeremiah Milbauer, Carnegie Mellon University, Pittsburgh PA, USA (email: {jmilbaue | sherryw}@cs.cmu.edu);
(2) Ziqi Ding, Carnegie Mellon University, Pittsburgh PA, USA (e-mail: {ziqiding | zhijinw}@andrew.cmu.edu)
(3) Tongshuang Wu, Carnegie Mellon University, Pittsburgh PA, USA.
Table of Links
- Abstract and Introduction
- Related Work
- The NEWSSENSE Framework
- Pilot Study
- System Overview
- Discussion
- Conclusion, Limitations and Ethics, and References
- A. Appendix: Prompt for Claim Extraction
5 System Overview
Following our user study, we implemented the NEWSSENSE framework as a browser plugin, which adds augmentations to news articles encountered on the web. Figure 1 shows the final appearance of the browser plugin. Code for system and plugin can be accessed at github.com/jmilbauer/NewsSense, and a demo video can be viewed at youtu.be/2D5LYbsQJak.
This section provides a description of the natural language processing system which powers NEWSSENSE. Figure 2 illustrates the four general steps of the pipeline: Collection, Selection, Filtering, and Linking.
5.1 Article Collection
First, we must collect a cluster of news articles that are all about the same news event. Our implementation scrapes data from Google News Stories, a website that collects many articles about the same events across news venues. After collecting article URLs via Google News Stories, we then collect the content of each article. A typical story contains over 50 articles.
5.2 Claim Selection
The next phase of the pipeline is to select the claims within each article cluster. We initially assumed a 1-to-1 mapping between sentences and claims, but quickly found that news articles often contain complex multi-clause sentences, which are not suitable for natural language inference. To address this issue, we few-shot prompting to generate a list of claims from sentences using a large language model (LLM). In our experiments, prompt exemplars are drawn from the PROPSEGMENT dataset (Chen et al., 2022), and the LLM used is OpenAI text-davinci-003. Full prompt details are provided in Appendix A. We also note that the authors of PROPSEGMENT report that T5-Large performs reasonably well on the task, suggesting the possibility for further pipeline improvements.
5.3 Claim Filtering
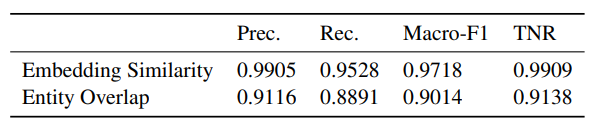
Articles often contain over 30 sentences. For a cluster of 50 articles, a pairwise comparison of the full cartesian product of sentences has O((NL) 2 ), which is in practice well over 1,000,000 comparisons. Performing this level of computation at scale, even if we are pre-computing results for each article cluster, is simply not feasible. To address this, we perform an initial filtering step with leverages the fact that the vast majority of claims across any two articles are unrelated. We consider two approaches for claim filtering: Embedding Similarity filtering (ES) and Lexical Overlap filtering (LeO).
For Embedding Similarity filtering, we encode each claim in each article using a Transformerbased sentence encoder. Then, for each claim we retain only the k most similar other claims for comparison. In our implementation, we use the Sentence Transformers (Reimers and Gurevych, 2019) all-Mini-LM-L6-v2.
For Lexical Overlap filtering, we compare each sentence only with sentences that have overlapping words, as these sentences are likely to discuss similar topics. In our implementation, we process claims by first remove stopwords, then stemming using the NLTK (Loper and Bird, 2002) implementation of the Porter Stemmer (Porter, 1980), and compute overlap scores using the Jaccard Index.
We evaluated each filtering method on the MNLI (Williams et al., 2017) validation data, treating pairs of randomly sampled sentences as negative examples, and labeled “entailment" and “contradiction" sentence pairs as positive examples. For ES, we set a threshold of 0.3 cosine similarity; for LeO, we set a threshold of 0.1 overlap. We note that all-Mini-LM-L6-v2 included MNLI in its training data.
We include a summary of the results of these experiments in Table 1, which indicates that the ES method outperforms the LeO method. Of particular interest is the true negative rate, as this indicates the percentage of non-related sentences we expect to filter out.
5.4 Claim Linking
Once claim pairs have been filtered, we classify each pair according to the Natural Language Inference (NLI) framework, as “entailment," “contradiction," or “neutral." We employ a pretrained language model, RoBERTa (Liu et al., 2019), which was then fine-tuned on MNLI (Williams et al., 2017), a popular dataset for NLI. We download this fine-tuned version of RoBERTa from the Hugging Face model library [11]. To avoid clutter, we keep fewer than 100 of the most confident predictions for each positive class (entailment or contradiction) within the article cluster. Claims are then assigned back to the sentences from which they were generated, and the sentence pairs are linked.
[11] https://huggingface.co/roberta-large-mnli