Authors:
(1) Troisemaine Colin, Department of Computer Science, IMT Atlantique, Brest, France., and Orange Labs, Lannion, France;
(2) Reiffers-Masson Alexandre, Department of Computer Science, IMT Atlantique, Brest, France.;
(3) Gosselin Stephane, Orange Labs, Lannion, France;
(4) Lemaire Vincent, Orange Labs, Lannion, France;
(5) Vaton Sandrine, Department of Computer Science, IMT Atlantique, Brest, France.
Table of Links
Estimating the number of novel classes
Appendix A: Additional result metrics
Appendix C: Cluster Validity Indices numerical results
Appendix D: NCD k-means centroids convergence study
5 Estimating the number of novel classes
Cluster Validity Indices (CVIs) are commonly used in unsupervised data analysis to estimate the number of clusters and are also applicable to the NCD problem. CVIs are scores that compare the compactness and separation of clusters without the help of external information such as ground truth labels. However, the knowledge from the known classes isn’t used if the CVIs are directly applied to estimate the number of novel classes. Therefore, we propose to apply the CVIs in the latent representation learned by PBN. Projection-based NCD methods such as PBN are designed to create a latent space that emphasizes the relevant features of the known classes. Since these features are shared to some extent with the novel classes, this representation should be better at revealing the clusters we are trying to discover than the original feature space. Consequently, it makes sense that applying the different estimation techniques in the learned latent space should yield better results.
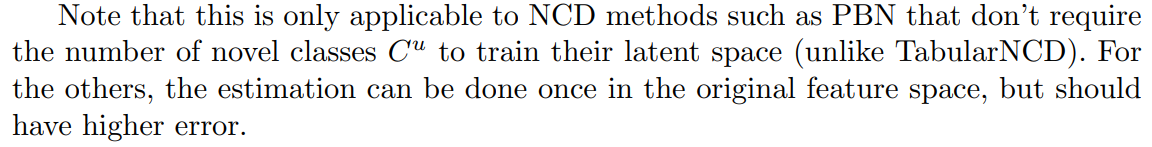
Some NCD works have also previously attempted to estimate the number of novel classes. For instance, [3] defines a large number of output neurons in their clustering network (e.g. 100). In this case, the clustering network is expected to use only the necessary number of clusters while leaving the remaining output neurons unused. Clusters were counted if they contained more instances than a certain threshold. However, since, with the exception of TabularNCD, the models studied in this paper do not use a clustering network, we will not evaluate this method.

To select the CVI that we will use for our application, we rely on the results of [33]. Here, the authors conducted an extensive performance evaluation of 30 CVIs. They concluded that the Silhouette, Davies–Bouldin, Calinski–Harabasz and Dunn indices behaved better than other indices in almost all cases. In the experiments, the performance of these 4 indices will be compared, with the addition of the elbow method and the NCD-specific method KM-ACC.
This paper is available on arxiv under CC 4.0 license.