Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
5.1 Disentangling Semantics and Syntax in Sentence Representations
5.1.1 Introduction
As generative latent variable models, especially of the continuous variety (Kingma and Welling, 2014; Goodfellow et al., 2014), have become increasingly important in natural language processing (Bowman et al., 2016; Gulrajani et al., 2017), there has been increased interest in learning models where the latent representations are disentangled (Hu et al., 2017). Much of the recent NLP work on learning disentangled representations of text has focused on disentangling the representation of attributes such as sentiment from the representation of content, typically in an effort to better control text generation (Shen et al., 2017a; Zhao et al., 2017; Fu et al., 2018).
In this work, we instead focus on learning sentence representations that disentangle the syntax and the semantics of a sentence. We are moreover interested in disentangling these representations not for the purpose of controlling generation, but for the purpose of calculating semantic or syntactic similarity between sentences (but not both). To this end, we propose a generative model of a sentence which makes use of both semantic and syntactic latent variables, and we evaluate the induced representations on both standard semantic similarity tasks and on several novel syntactic similarity tasks.
We use a deep generative model consisting of von Mises Fisher (vMF) and Gaussian priors on the semantic and syntactic latent variables (respectively) and a deep bag-of-words decoder that conditions on these latent variables. Following much recent work, we learn this model by optimizing the ELBO with a VAE-like (Kingma and Welling, 2014; Rezende et al., 2014) approach.
Our learned semantic representations are evaluated on the SemEval semantic textual similarity (STS) tasks (Agirre et al., 2012; Cer et al., 2017). Because there has been less work on evaluating syntactic representations of sentences, we propose several new syntactic evaluation tasks, which involve predicting the syntactic analysis of an unseen sentence to be the syntactic analysis of its nearest neighbor (as determined by the latent syntactic representation) in a large set of annotated sentences.
In order to improve the quality and disentanglement of the learned representations, we incorporate simple additional losses in our training, which are designed to force the latent representations to capture different information. In particular, our semantic multi-task losses make use of aligned paraphrase data, whereas our syntactic multi-task loss makes use of word-order information. Additionally, we explore different encoder and decoder architectures for learning better syntactic representations.
Experimentally, we find that by training in this way we are able to force the learned representations to capture different information (as measured by the performance gap between the latent representations on each task). Moreover, we find that we achieve the best performance on all tasks when the learned representations are most disentangled.
5.1.2 Related Work
There is a growing amount of work on learning interpretable or disentangled latent representations in various NLP applications, including sentence sentiment and style transfer (Hu et al., 2017; Shen et al., 2017a; Fu et al., 2018; Zhao et al., 2018, inter alia), morphological reinflection (Zhou and Neubig, 2017), semantic parsing (Yin et al., 2018), text generation (Wiseman et al., 2018), and sequence labeling (Chen et al., 2018a). Another related thread of work is text-based variational autoencoders (Miao et al., 2016; Bowman et al., 2016).
In terms of syntax and semantics in particular, there is a rich history of work in analyzing their interplay in sentences (Jurafsky, 1988; van Valin, Jr., 2005). We do not intend to claim that the two can be entirely disentangled in distinct representations. Rather, our goal is to propose modica of knowledge via particular multi-task losses and measure the extent to which this knowledge leads learned representations to favor syntactic or semantic information from a sentence.
There has been prior work with similar goals for representations of words (Mitchell and Steedman, 2015) and bilexical dependencies (Mitchell, 2016), finding that decomposing syntactic and semantic information can lead to improved performance on semantic tasks. We find similar trends in our results, but at the level of sentence representations. A similar idea has been explored for text generation (Iyyer et al., 2018), where adversarial examples are generated by controlling syntax.
Some of our losses use sentential paraphrases, relating them to work in paraphrase modeling (Wieting et al., 2016; Wieting and Gimpel, 2018). Deudon (2018) proposed a variational framework for modeling paraphrastic sentences and Chen and Gimpel (2020) learned probabilistic representations from paraphrases, but our focus here is on learning disentangled representations.
As part of our evaluation, we develop novel syntactic similarity tasks for sentence representations learned without any syntactic supervision. These evaluations relate to the broad range of work in unsupervised parsing (Klein and Manning, 2004) and part-of-speech tagging (Christodoulopoulos et al., 2010). However, our evaluations differ from previous evaluations in that we employ k-nearest-neighbor syntactic analyzers using our syntactic representations to choose nearest neighbors. There is a great deal of work on applying multi-task learning to various NLP tasks (Plank et al., 2016; Rei, 2017; Augenstein and Søgaard, 2017; Bollmann et al., 2018, inter alia) and, recently, as a way of improving the quality or disentanglement of learned representations (Zhao et al., 2017; Goyal et al., 2017; Du et al., 2018; John et al., 2019).
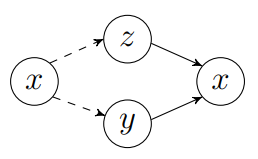
5.1.3 Model and Parameterization
Our goal is to extract the disentangled semantic and syntactic information from sentence representations. To achieve this, we introduce the vMF-Gaussian Variational Autoencoder (VGVAE). As shown in Fig. 5.1, VGVAE assumes a sentence is generated by conditioning on two independent variables: semantic variable y and syntactic variable z. In particular, our model gives rise to the following joint likelihood


VGVAE uses two distribution families in defining the posterior over latent variables, namely, the von Mises-Fisher (vMF) distribution and the Gaussian distribution (See Section 2.3.2 for background materials on these two distributions).



In the following sections, we will introduce several losses that will be added into the training of our base model, which empirically shows the ability of further disentangling the functionality between the semantic variable y and the syntactic variable z.
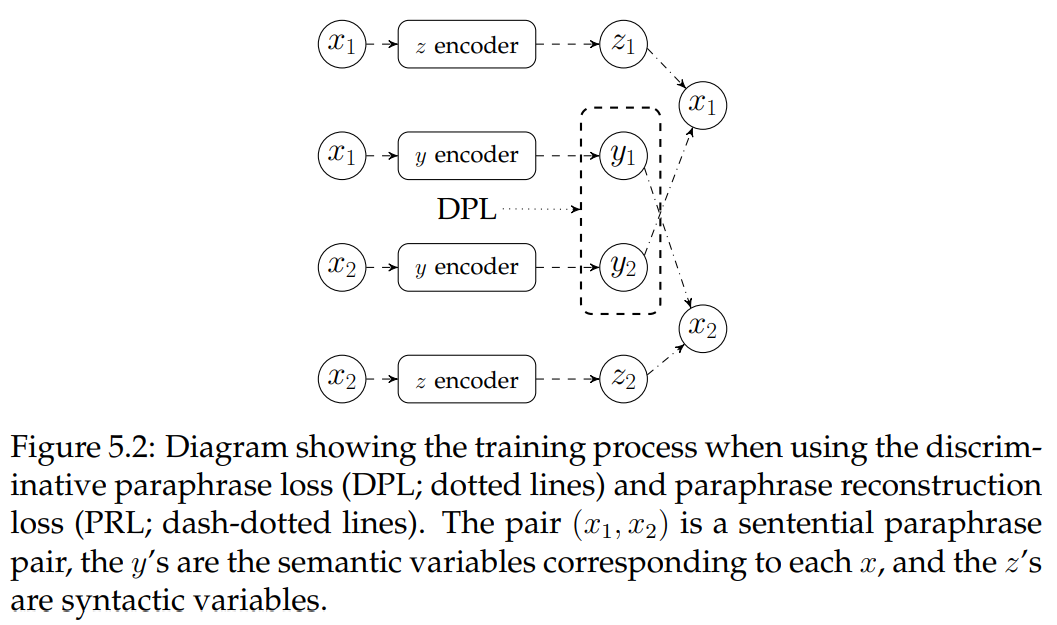
5.1.4 Multi-Task Training
We attempt to improve the quality and disentanglement of our semantic and syntactic representations by introducing additional losses, which encourage y to capture semantic information and z to capture syntactic information. We elaborate on these losses below.


The similarity function we choose is the cosine similarity between the mean directions of the semantic variables from the two sentences:
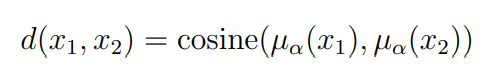
Word Position Loss It has been observed in previous work that word order typically contributes little to the modelling of semantic similarity (Wieting et al., 2016). We interpret this as evidence that word position information is more relevant to syntax than semantics, at least as evaluated by STS tasks. To guide the syntactic variable to represent word order, we introduce a word position loss (WPL). Although our word averaging encoders only have access to the bag of words of the input, using this loss can be viewed as a denoising autoencoder where we have maximal input noise (i.e., an order less representation of the input) and the encoders need to learn to reconstruct the ordering.

5.1.5 Experimental Setup
KL Weight. Following previous work on VAEs (Higgins et al., 2017; Alemi et al., 2017), we attach a weight to the KL divergence and tune it based on development set performance.
Negative Samples. When applying DPL, we select negative samples based on maximizing cosine similarity to sentences from a subset of the data. In particular, we accumulate k mini-batches during training, yielding a “mega-batch” S (Wieting and Gimpel, 2018). Then the negative samples are selected based on the following criterion:

Training Setup. We subsampled half a million paraphrase pairs from ParaNMT50M (Wieting and Gimpel, 2018) as our training set. We use SemEval semantic textual similarity (STS) task 2017 (Cer et al., 2017) as a development set. For semantic similarity evaluation, we use the STS tasks from 2012 to 2016 (Agirre et al., 2012, 2013, 2014, 2015, 2016) and the STS benchmark test set (Cer et al., 2017). For evaluating syntactic similarity, we propose several evaluations. One uses the gold parse trees from the Penn Treebank (Marcus et al., 1993), and the others are based on automatically tagging and parsing five million paraphrases from ParaNMT-50M; we describe these tasks in detail below.
For hyperparameters, the dimensions of the latent variables are 50. The dimensions of word embeddings are 50. We use cosine similarity as similarity metric for all of our experiments. We tune the weights for PRL and reconstruction loss from 0.1 to 1 in increments of 0.1 based on the development set performance. We use one sample from each latent variable during training. When evaluating VGVAE based models on STS tasks, we use the mean direction of the semantic variable y, while for syntactic similarity tasks, we use the mean vector of the syntactic variable z.
Baselines Our baselines are a simple word averaging (WORDAVG) model and bidirectional LSTM averaging (BLSTMAVG) model, both of which have been shown to be very competitive for modeling semantic similarity when trained on paraphrases (Wieting and Gimpel, 2018). Specifically, WORDAVG takes the average over the word embeddings in the input sequence to obtain the sentence representation. BLSTMAVG uses the averaged hidden states of a bidirectional LSTM as the sentence representation, where forward and backward hidden states are concatenated. These models use 50 dimensional word embeddings and 50 dimensional LSTM hidden vectors per direction. These baselines are trained with DPL only. Additionally, we scramble the input sentence for BLSTMAVG since it has been reported beneficial for its performance in semantic similarity tasks (Wieting and Gimpel, 2017).
We also benchmark several pretrained embeddings on both semantic similarity and syntactic similarity datasets, including GloVe,[1] Skip-thought,[2] InferSent,[3] ELMo,[4] and BERT.[5] For GloVe, we average word embeddings to form sentence embeddings. For ELMo, we average the hidden states from three layers and then average the hidden states across time steps. For BERT, we use the averaged hidden states from the last attention block. Code is available at https://github.com/ mingdachen/disentangle-semantics-syntax.
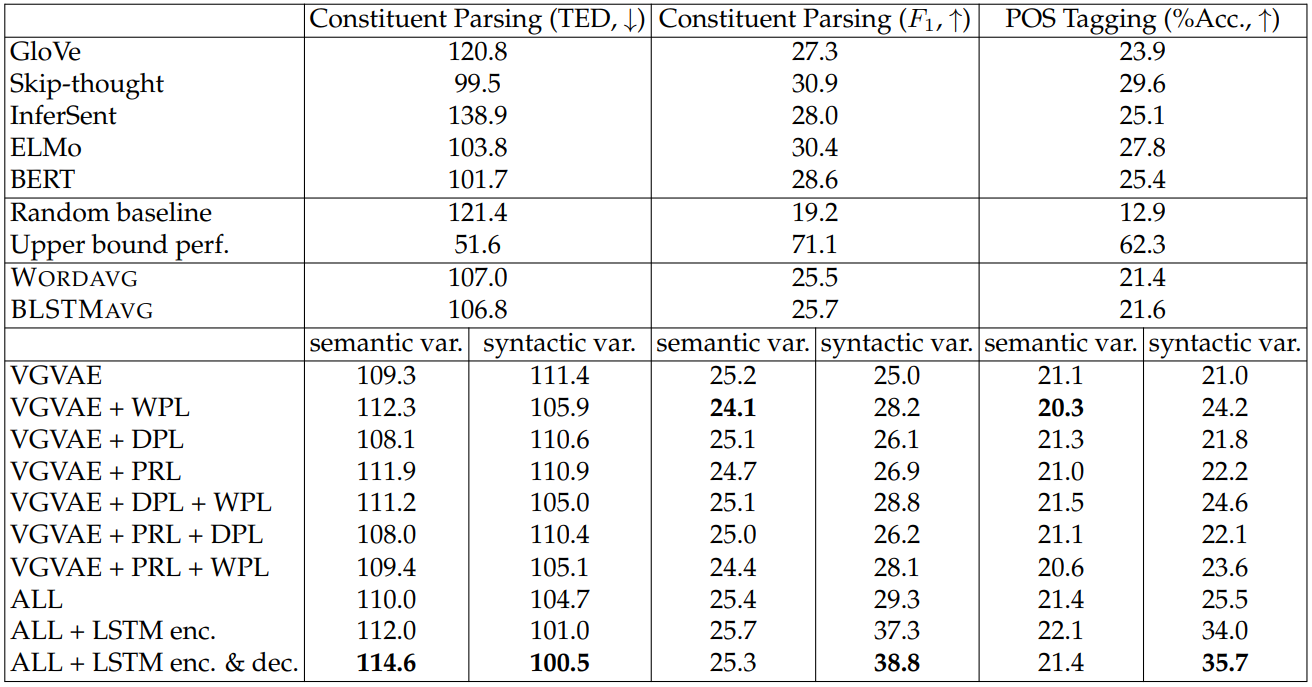
5.1.6 Experimental Results
Semantic Similarity. As shown in Table 5.1, the semantic and syntactic variables of our base VGVAE model show similar performance on the STS test sets. As we begin adding multi-task losses, however, the performance of these two variables gradually diverges, indicating that different information is being captured in the
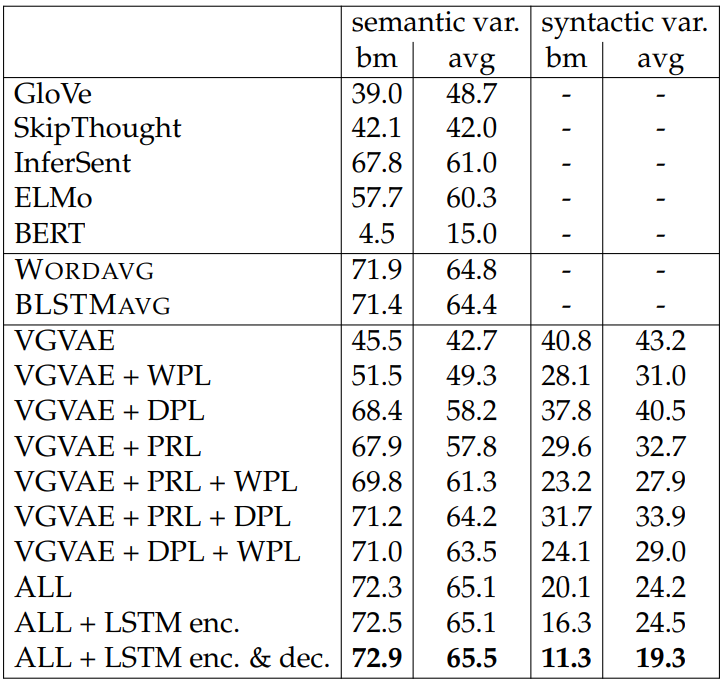
two variables. More interestingly, note that when any of the three losses is added to the base VGVAE model (even the WPL loss which makes no use of paraphrases), the performance of the semantic variable increases and the performance of the syntactic variable decreases; this suggests that each loss is useful in encouraging the latent variables to learn complementary information.
Indeed, the trend of additional losses both increasing semantic performance and decreasing syntactic performance holds even as we use more than two losses, except for the single case of VGVAE + PRL + DPL, where the syntactic performance increases slightly. Finally, we see that when the bag-of-words VGVAE model is used with all of the multi-task losses (“ALL”), we observe a large gap between the performance of the semantic and syntactic latent variables, as well as strong performance on the STS tasks that outperforms all baselines.
Using LSTM modules further strengthens the disentanglement between the two variables and leads to even better semantic performance. While using an LSTM encoder and a bag-of-words decoder is difficult to justify from a generative modeling perspective, we include results with this configuration to separate out the contributions of the LSTM encoder and decoder.
Syntactic Similarity. So far, we have only confirmed empirically that the syntactic variable has learned to not capture semantic information. To investigate what the syntactic variable has captured, we propose several syntactic similarity tasks.
In particular, we consider using the syntactic latent variable in calculating nearest neighbors for a 1-nearest-neighbor syntactic parser or part-of-speech tagger. We use our latent variables to define the similarity function in these settings and evaluate the quality of the output parses and tag sequences using several metrics.
Our first evaluation involves constituency parsing, and we use the standard training and test splits from the Penn Treebank. We predict a parse tree for each sentence in the test set by finding its nearest neighbor in the training set based on the cosine similarity of the mean vectors for the syntactic variables. The parse tree of the nearest neighbor will then be treated as our prediction for the test sentence. Since the train and test sentences may differ in length, standard parse evaluation metrics are not applicable, so we use tree edit distance Zhang and Shasha (1989) [6] to compute the distance between two parse tree without considering word tokens.
To better understand the difficulty of this task, we introduce two baselines. The first randomly selects a training sentence. We calculate its performance by running it ten times and then reporting the average. We also report the upper bound performance given the training set. Since computing tree edit distance is time consuming, we subsample 100 test instances and compute the minimum tree edit distance for each sampled instance. Thus, this number can be seen as the approximated upper bound performance for this task given the training set.
To use a more standard metric for these syntactic similarity tasks, we must be able to retrieve training examples with the same number of words as the sentence we are trying to parse. We accordingly parse and tag the five million paraphrase subset of the ParaNMT training data using Stanford CoreNLP (Manning et al., 2014). To form a test set, we group sentences in terms of sentence length and subsample 300 sentences for each sentence length. After removing the paraphrases of the sentences in the test set, we use the rest of the training set as candidate sentences for nearest neighbor search, and we restrict nearest neighbors to have the same sentence length as the sentence we are attempting to parse or tag, which allows us to use standard metrics like labeled F1 score and tagging accuracy for evaluation.
As shown in Table 5.2, the syntactic variables and semantic variables demonstrate similar trends across these three syntactic tasks. Interestingly, both DPL and PRL help to improve the performance of the syntactic variables, even though these two losses are only imposed on the semantic variables. We saw an analogous pattern in Table 5.1, which again suggests that by pushing the semantic variables to learn information shared by paraphrastic sentences, we also encourage the syntactic variables to capture complementary syntactic information. We also find that adding WPL brings the largest improvement to the syntactic variable, and keeps the syntactic information carried by the semantic variables at a relatively low level. Finally, when adding all three losses, the syntactic variable shows the strongest performance across the three tasks.

In addition, we observe that the use of the LSTM encoder improves syntactic performance by a large margin and the LSTM decoder improves further, which suggests that the use of the LSTM decoder contributes to the amount of syntactic information represented in the syntactic variable.
Among pretrained representations, Skip-thought shows the strongest performance overall and ELMo has the second best performance in the last two columns. While InferSent performs worst in the first column, it gives reasonable performance for the other two. BERT performs relatively well in the first column but worse in the other two.
5.1.7 Analysis
Qualitative Analysis. To qualitatively evaluate our latent variables, we find (via cosine similarity) nearest neighbor sentences to test set examples in terms of both the semantic and syntactic representations. We also find nearest neighbors of words (which we view as single-word sentences). We discuss the results of this analysis below.
Lexical Analysis. Table 5.3 shows word nearest neighbors for both syntactic and semantic representations. We see that the most similar words found by the syntactic variable share the same part-of-speech tags with the query words. For example,
“starting” is close to “getting” and “taking,” even though these words are not semantically similar. Words retrieved according to the semantic variable, however, are more similar semantically, e.g., “begin” and “starts”. As another example, “times” is similar to words that are either related to descriptions of frequency (e.g., “twice” and “often”) or related to numbers (e.g., “thousand”, “seven”).
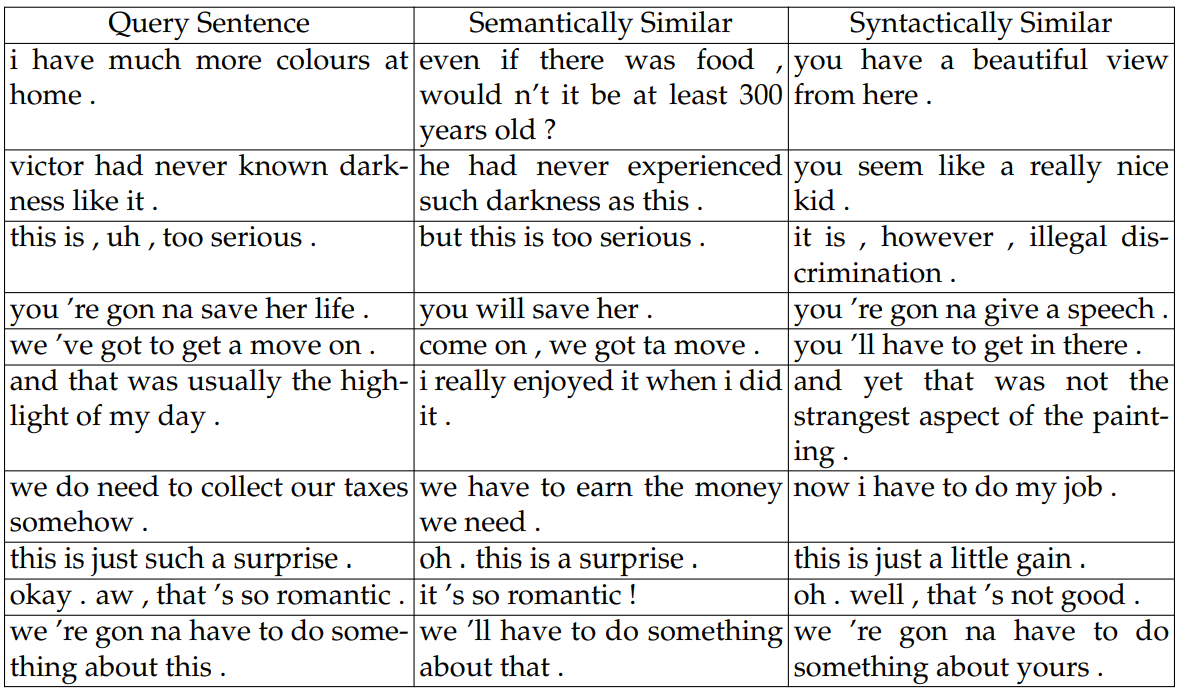
Sentential Analysis. As shown in Table 5.4, sentences that are similar in terms of their semantic variables tend to have similar semantics. However, sentences that are similar in terms of their syntactic variables are mostly semantically unrelated but have similar surface forms. For example, “you ’re gon na save her life .” has the same meaning as “you will save her .” while having a similar syntactic structure to “you ’re gon na give a speech .” (despite having very different meanings). As another example, although the semantic variable does not find a good match for “i have much more colours at home .”, which can be attributed to the limited size of candidate sentences, the nearest syntactic neighbor (“you have a beautiful view from here .”) has a very similar syntactic structure to the query sentence.
This paper is available on arxiv under CC 4.0 license.
[1] We use 300 dimensional Common Crawl embeddings available at nlp.stanford.edu/ projects/glove
[2] github.com/ryankiros/skip-thoughts
[3] We use model V1 available at github.com/facebookresearch/InferSent
[4] We use the original model available at allennlp.org/elmo
[5] We use bert-large-uncased available at github.com/huggingface/ pytorch-pretrained-BERT
[6] github.com/timtadh/zhang-shasha