
Authors:
(1) Sasun Hambardzumyan, Activeloop, Mountain View, CA, USA;
(2) Abhinav Tuli, Activeloop, Mountain View, CA, USA;
(3) Levon Ghukasyan, Activeloop, Mountain View, CA, USA;
(4) Fariz Rahman, Activeloop, Mountain View, CA, USA;.
(5) Hrant Topchyan, Activeloop, Mountain View, CA, USA;
(6) David Isayan, Activeloop, Mountain View, CA, USA;
(7) Mark McQuade, Activeloop, Mountain View, CA, USA;
(8) Mikayel Harutyunyan, Activeloop, Mountain View, CA, USA;
(9) Tatevik Hakobyan, Activeloop, Mountain View, CA, USA;
(10) Ivo Stranic, Activeloop, Mountain View, CA, USA;
(11) Davit Buniatyan, Activeloop, Mountain View, CA, USA.
Table of Links
- Abstract and Intro
- Current Challenges
- Tensor Storage Format
- Deep Lake System Overview
- Machine Learning Use Cases
- Performance Benchmarks
- Discussion and Limitations
- Related Work
- Conclusions, Acknowledgement, and References
4. DEEP LAKE SYSTEM OVERVIEW
As shown in Fig. 1, Deep Lake stores raw data and views in object storage such as S3 and materializes datasets with full lineage. Streaming, Tensor Query Language queries, and Visualization engine execute along with either deep learning compute or on the browser without requiring external managed or centralized service.
4.1 Ingestion
4.1.1 Extract. Sometimes metadata might already reside in a relational database. We additionally built an ETL destination connector using Airbyte[3] [22]. The framework allows plugging into any supported data source, including SQL/NoSQL databases, data lakes, or data warehouses, and synchronizing the data into Deep Lake. Connector protocol transforms the data into a columnar format.
4.1.2 Transform. To significantly accelerate data processing workflows and free users from worrying about the chunk layout, Deep Lake provides an option to execute python transformations in parallel. The transformation takes in a dataset, sample-wise iterates across the first dimension, and outputs a new dataset. A user defined python function expects two required arguments 𝑠𝑎𝑚𝑝𝑙𝑒_𝑖𝑛, 𝑠𝑎𝑚𝑝𝑙𝑒_𝑜𝑢𝑡 and is decorated with @𝑑𝑒𝑒𝑝𝑙𝑎𝑘𝑒.𝑐𝑜𝑚𝑝𝑢𝑡𝑒. A single 𝑠𝑎𝑚𝑝𝑙𝑒_𝑖𝑛 can dynamically create multiple 𝑠𝑎𝑚𝑝𝑙𝑒_𝑜𝑢𝑡𝑠. It enables both one-to-one and one-to-many transformations. The transformation can also be applied in place without creating a new dataset.
Behind the scenes, the scheduler batches sample-wise transformations operating on nearby chunks and schedule them on a process pool. Optionally, the compute can be delegated to a Ray cluster [53]. Instead of defining an input dataset, the user can provide an arbitrary iterator with custom objects to create ingestion workflows. Users can also stack together multiple transformations and define complex pipelines.
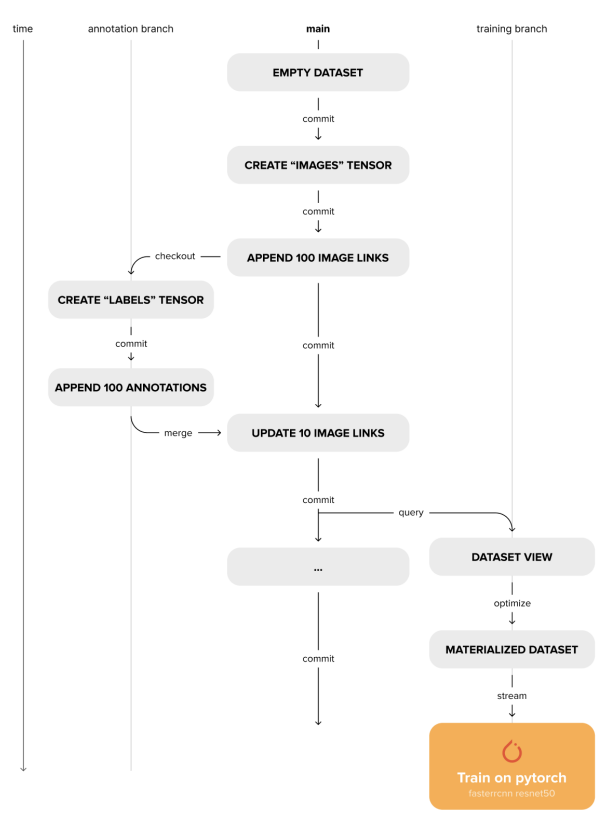
4.2 Version Control
Deep Lake also addresses the need for the reproducibility of experiments and compliance with a complete data lineage. Different versions of the dataset exist in the same storage, separated by sub-directories. Each sub-directory acts as an independent dataset with its metadata files. Unlike a non-versioned dataset, these subdirectories only contain chunks modified in the particular version, along with a corresponding chunk_set per tensor containing the names of all the modified chunks. A version control info file present at the root of the directory keeps track of the relationship between these versions as a branching version-control tree. While accessing any chunk of a tensor at a particular version, the version control tree is traversed starting from the current commit, heading towards the first commit. During the traversal, the chunk set of each version is checked for the existence of the required chunk. If the chunk is found, the traversal is stopped, and data is retrieved. For keeping track of differences across versions, for each version, a commit diff file is also stored per tensor. This makes it faster to compare across versions and branches. Moreover, the ids of samples are generated and stored during the dataset population. This is important for keeping track of the same samples during merge operations. Deep Lake’s version control interface is the Python API, which enables machine learning engineers to version their datasets within their data processing scripts without switching back and forth from the CLI. It supports the following commands:
• Commit: creates an immutable snapshot of the current state of the dataset.
• Checkout: checks out to an existing branch/commit or creates a new branch if one doesn’t exist.
• Diff: compares the differences between 2 versions of the dataset.
• Merge: merges two different versions of the dataset, resolving conflicts according to the policy defined by the user.
4.3 Visualization of Tensors
Data visualization is a crucial part of ML workflows, especially when the data is hard to parse analytically. Fast and seamless visualization allows faster data collection, annotation, quality inspection, and training iterations. The Deep Lake visualizer engine provides a web interface for visualizing large-scale data directly from the source. It considers htype of the tensors to determine the best layout for visualization. Primary tensors, such as image, video and audio are displayed first, while secondary data and annotations, such as text, class_label, bbox and binary_mask are overlayed. The visualizer also considers the meta type information, such as sequence to provide a sequential view of the data, where sequences can be played and jump to the specific position of the sequence without fetching the whole data, which is relevant for video or audio use cases. Visualizer addresses critical needs in ML workflows, enabling users to understand and troubleshoot the data, depict its evolution, compare predictions to ground truth or display multiple sequences of images (e.g., camera images and disparity maps) side-by-side.
4.4 Tensor Query Language
Querying and balancing datasets is a common step in training deep learning workflows. Typically, this is achieved inside a dataloader using sampling strategies or separate pre-processing steps to subselect the dataset. On the other hand, traditional data lakes connect to external analytical query engines [66] and stream Dataframes to data science workflows. To resolve the gap between the format and fast access to the specific data, we provide an embedded SQL-like query engine implemented in C++ called Tensor Query Language (TQL). An example query is shown at Fig. 5. While SQL parser has been extended from Hyrise [37] to design Tensor Query Language, we implemented our planner and execution engine that can optionally delegate computation to external tensor computation frameworks. The query plan generates a computational graph of tensor operations. Then the scheduler, executes the query graph.

Execution of the query can be delegated to external tensor computation frameworks such as PyTorch [58] or XLA [64] and efficiently utilize underlying accelerated hardware. In addition to standard SQL features, TQL also implements numeric computation. There are two main reasons for implementing a new query language. First, traditional SQL does not support multidimensional array operations such as computing the mean of the image pixels or projecting arrays on a specific dimension. TQL solves this by adding Python/NumPy-style indexing, slicing of arrays, and providing a large set of convenience functions to work with arrays, many of which are common operations supported in NumPy. Second, TQL enables deeper integration of the query with other features of the Deep Lake, such as version control, streaming engine, and visualization. For example, TQL allows querying data on specific versions or potentially across multiple versions of a dataset. TQL also supports specific instructions to customize the visualization of the query result or seamless integration with the dataloader for filtered streaming. The embedded query engine runs along with the client either while training a model on a remote compute instance or in-browser compiled over WebAssembly. TQL extends SQL with numeric computations on top of multi-dimensional columns. It constructs views of datasets, which can be visualized or directly streamed to deep learning frameworks. Query views, however, can be sparse, which can affect streaming performance.
4.5 Materialization
Most of the raw data used for deep learning is stored as raw files (compressed in formats like JPEG), either locally or on the cloud. A common way to construct datasets is to preserve pointers to these raw files in a database, query this to get the required subset of data, fetch the filtered files to a machine, and then train a model iterating over files. In addition, data lineage needs to be manually maintained with a provenance file. Tensor Storage Format simplifies these steps using linked tensors - storing pointers (links/urls to one or multiple cloud providers) to the original data. The pointers within a single tensor can be connected to multiple storage providers, thus allowing users to get a consolidated view of their data present in multiple sources. All of Deep Lake’s features including queries, version control, and streaming to deep learning frameworks can be used with linked tensors. However, the performance of data streaming will not be as optimal as default tensors. A similar problem exists with sparse views created due to queries, which would be inefficiently streamed due to the chunk layout. Furthermore, materialization transforms the dataset view into an optimal layout to stream into deep learning frameworks to iterate faster. Materialization involves fetching the actual data from links or views and efficiently laying it out into chunks. Performing this step towards the end of machine learning workflows leads to minimum data duplication while ensuring optimal streaming performance and minimal data duplication, with full data lineage.
4.6 Streaming Dataloader
As datasets become larger, storing and transferring over the network from a remotely distributed storage becomes inevitable. Data streaming enables training models without waiting for all of the data to be copied to a local machine. The streaming dataloader ensures data fetching, decompression, applying transformations, collation, and data handover to the training model. Deep learning dataloaders typically delegate fetching and transformation to parallel running processes to avoid synchronous computation. Then the data is transferred to the main worker through inter-process communication (IPC) which introduces memory copy overhead or uses shared memory with some reliability issues. In contrast, Deep Lake dataloader delegates highly parallel fetching and in-place decompressing in C++ per process to avoid global interpreter lock. Then, it passes the in-memory pointer to the user-defined transformation function and collates before exposing them to the training loop in deep learning native memory layout. Transformation concurrently executes in parallel when it uses only native library routine calls and releases python global interpreter lock (GIL) accordingly. As a result, we get:
• Performance: Delivering data to the deep learning model fast enough so that either the GPU is fully utilized or bottlenecked by the compute.
• Smart Scheduler: Dynamically differentiating between CPU-intensive jobs prioritization over less-intensive.
• Efficient Resource Allocation: Predicting memory consumption to avoid breaking the training process due to memory overfilling.
This paper is available on arxiv under CC 4.0 license.
[3] Source code available: https://github.com/activeloopai/airbyte on the branch @feature/connector/deeplake