
Authors:
(1) Gladys Tyen, University of Cambridge, Dept. of Computer Science & Technology, ALTA Institute, and Work done during an internship at Google Research (e-mail: gladys.tyen@cl.cam.ac.uk);
(2) Hassan Mansoor, Google Research (e-mail: hassan@google.com);
(3) Victor Carbune, Google Research (e-mail: vcarbune@google.com);
(4) Peter Chen, Google Research and Equal leadership contribution (chenfeif@google.com);
(5) Tony Mak, Google Research and Equal leadership contribution (e-mail: tonymak@google.com).
Table of Links
Conclusion, Limitations, and References
2 BIG-Bench Mistake
BIG-Bench Mistake consists of 2186 sets of CoTstyle traces. Each trace was generated by PaLM 2-L-Unicorn, and annotated with the location of the first logical error. An example trace is shown in Table 1, where the mistake location3 is the 4th step. Our traces span across a set of 5 tasks4 from the BIG-bench dataset (Srivastava et al., 2023): word sorting, tracking shuffled objects, logical deduction, multi-step arithmetic, and Dyck languages. CoT prompting is used to prompt PaLM 2 to answer questions from each task.
As we wanted to separate our CoT traces into distinct steps, we follow the method used by Yao et al. (2022) and generate each step separately, using the newline as a stop token.

In this dataset, all traces are generated with temperature = 0. The correctness of answers are determined by exact match. Prompts can be found at https://github.com/WHGTyen/ BIG-Bench-Mistake.
2.1 Annotation
Each generated trace is annotated with the first logical error. We ignore any subsequent errors as they may be dependent on the original error.
Note that traces can contain a logical mistake yet arrive at the correct answer. To disambiguate the two types of correctness, we will use the terms correctans and incorrectans to refer to whether the final answer of the trace is correct. Accuracyans would therefore refer to the overall accuracy for the task, based on how many final answers are correct.
To refer to whether the trace contains a logical mistake (rather than the correctness of the final answer), we will use correctmis and incorrectmis.
2.1.1 Hman annotation
For 4 of the 5 tasks, we recruit human annotators to go through each trace and identify any errors. Annotators have no domain expertise but are given guidelines5 to complete the task.
Before annotation, we sample a set of 300 traces for each task, where 255 (85%) are incorrectans, and 45 (15%) are correctans. Since human annotation is a limited and expensive resource, we chose this distribution to maximise the number of steps containing mistakes and to prevent over-saturation of correct steps.
We also include some correctans traces because some may contain logical errors despite the correct answer, and to ensure that the dataset included examples of correct steps that are near the end of the trace. This also prevents annotators from feeling forced to find a mistake in all traces.To account for this skewed distribution, results in section 4 are split according to whether the original trace is correctans or incorrectans.
Following Lightman et al. (2023), annotators are instructed to go through each step in the trace and indicate whether the step is correct or not (binary choice). Annotators only submit their answers until all steps have been annotated, or there is one incorrect step. If an incorrect step is identified, the remaining steps are skipped.
This is done to avoid ambiguities where a logically correct deduction is dependent on a previous mistake. We make our annotation guidelines available at https:// github.com/WHGTyen/BIG-Bench-Mistake, and we include a screenshot of the user interface in Figure 3.
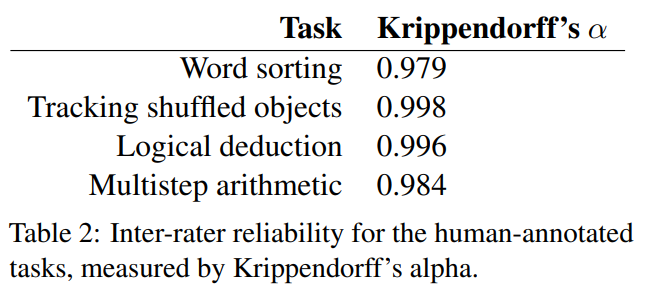
Each trace has been annotated by at least 3 annotators. If there are any disagreements, we take the majority label. We calculate Krippendorff’s alpha (Hayes and Krippendorff, 2007) to measure inter-rater reliability (see Table 2).
2.1.2 Automatic annotation
For Dyck languages, we opt for mostly automatic annotation instead of human annotation as the traces show limited variation in phrasing and solution paths.
For each trace, we generate a set of standard steps based on the format used in the prompt examples. Using pattern matching, we can identify whether each model-generated step also conforms to the same format. If so, we compare the two and assume that the trace is incorrect if the symbols do not match.
Additionally, we also account for edge cases such as where the final two steps are merged into one, or variations in presentation where some symbols are placed in quotes and some are not. We release the code at https://github.com/WHGTyen/ BIG-Bench-Mistake along with our dataset.
This paper is available on arxiv under CC 4.0 license.