
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Jiwan Chung, MIR Lab Yonsei University (https://jiwanchung.github.io/);
(2) Youngjae Yu, MIR Lab Yonsei University (https://jiwanchung.github.io/).
Table of Links
- Abstract and Intro
- Method
- Experiments
- Related Work
- Conclusion
- Limitations and References
- A. Experiment Details
- B. Prompt Samples
3. Experiments
For all experiments, we use GPT-3 [1] (text-davinci-003) as the backbone language model. Unless stated otherwise, we use the ground truth clip boundary to segment the videos. All LSS variants do not use any training data and thus are zero-shot methods.
![Table 3: Evaluation on the levels three and four of DramaQA validation split. CLIPCheck achieves state-of-the-art over the baselines and a prompt-based approach [35] of inputting image descriptions.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-vra30xo.png)
3.1. Evaluating Long Story Short
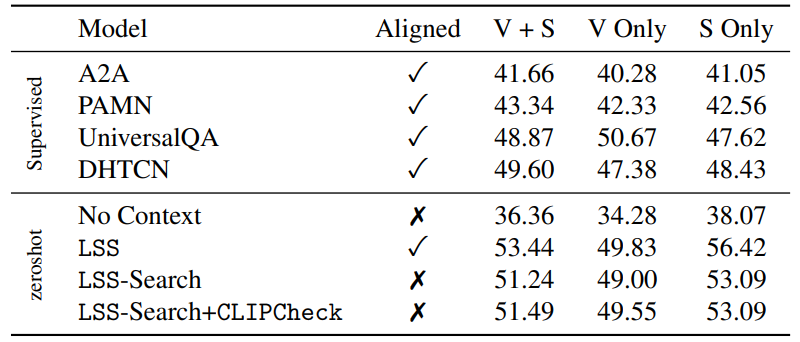
MovieQA [27] is a large-scale QA dataset sourced from 408 movies. There are multiple sources of information in the dataset; subtitles, scripts, DVS, video clips, and plots. We report four state-of-the-art supervised baselines; A2A [20], PAMN [11], UniversalQA [10], and DHTCN [21].
Table 1 shows zero-shot LSS improves over previous supervised approaches. Also, Ours-search shows strong performance even without the ground-truth segment index label. CLIPCheck slightly improves the accuracy in the video split. However, the difference is marginal since MovieQA often requires character-based grounding rather than general visual matching. Finally, we experiment with the null hypothesis: No Context tests whether GPT-3 solves MovieQA by simply memorizing every fact. No Context performs worse than LSS, rejecting the null hypothesis.
PororoQA [13] is a video story QA dataset built from a cartoon series. The supervised baseline takes the human-generated plot and the ground truth video segment index, while LSS +Plot+Search takes neither.
Table 2 summarizes our result on the PororoQA dataset. When using both the ground-truth episode and plots, GPT-3 performs almost on par with the supervised baseline. Substituting a human-generated summary with a model-generated one results in only a marginal performance drop. Perhaps intriguingly, the search process works better when using model-generated plots. We attribute this result to the fact that the human annotations are not designed for episode discriminability.
3.2. Evaluating CLIPCheck
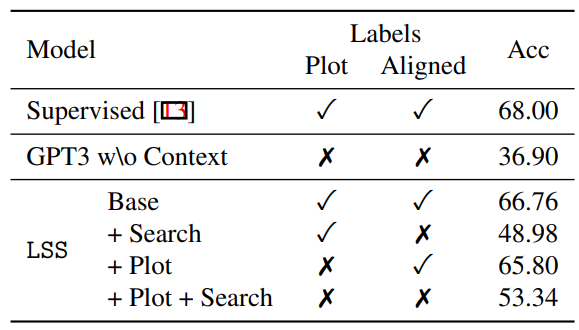
DramaQA [3] is video QA dataset that focuses on story understanding. The dataset is arranged with four levels of hierarchical difficulty, which follow the human cognitivedevelopmental stages. We evaluate LSS on the two high levels of DramaQA to test plot understanding. We report two latest baselines in level-wise DramaQA; CharacterAttention and Kim et al. [14].
We compare the effect of CLIPCheck and Caption, a prompt-based method of incorporating image frame descriptions extracted from BLIP [18] as inputs to GPT-3. Table 3 shows that CLIPCheck offers greater improvement than image descriptions. Also, while adding image captions improves LSS, the gain disappears when used jointly with CLIPCheck. We suspect that this is because frame captions provide similar information to CLIPCheck while being much noisier. Note that the automatic Captions here are not an integral component of LSS. As DramaQA has visually grounded annotations already, adding automatic image Captions on top of that would not necessarily improve the model performance. Rather, we use the Captions to explicitly compare early vs. late visual alignment methods.

Finally, we check whether CLIPCheck exploits the dataset bias rather than understanding the visual context. To this end, we devise a variant of CLIPCheck with random visual context (CLIPCheck-Shuffle). CLIPCheck-Shuffle does not improve over LSS with no CLIPCheck, denying the bias hypothesis.
3.3. Ablation Study
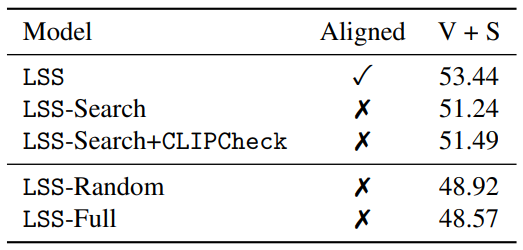
Are both the summarization and search important for narrative understanding? Here, we evaluate LSS variants with full context without the narrative search (LSS-Full) or with the plot summary and random segment as inputs (LSS-Random). Table 4 shows that both LSS-Full and LSS-Random fall behind LSS-Search, indicating the importance of retrieval. Note that we could not employ the full context in LSS-Full due to the token length limitation. Instead, we use the longest prefix of the full context that GPT3 accepts (4000 tokens minus the length of the instruction).

3.4. Qualitative Results
Figure 3 shows the automatic plot summary generated as an intermediate context of the long video QA using the language model in the LSS framework. As shown in the qualitative sample, the generated plots align well with the human-written plots from Wikipedia. For example, in the first scene of the movie "Harry Potter and the Deathly Hallows", the LSS summary correctly writes that Harry Potter is currently 17 years old and the main event in which the death eaters attack the protagonist.
Figure 4 depicts the connection between the searched plot piece and the answer likelihood. In the example on the left, the retrieved summary tells that Trench committed a crime and thus is on the run, suggesting that another character interested in him would be chasing him. The language model understands this context to modify the answer likelihood in the correct way. In the right example, the LSS plot piece suggests that Edward is confident in his decision. While this context does not offer a direct cue to the question, the language model sees it as information strong enough to alter the answer.